

来源:
中国基金报
国内两大 AI 巨头 DeepSeek(深度求索)、寒武纪罕见同步发布相关重要事项。
DeepSeek 官方微信号 9 月 29 日 18:07 发文称,「今天,我们正式发布 DeepSeek-V3.2-Exp 模型,这是一个实验性 (Experimental) 的版本。作为迈向新一代架构的中间步骤,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。目前,官方 App、网页端、小程序均已同步更新为 DeepSeek-V3.2-Exp,同时 API 大幅度降价,欢迎广大用户体验测试并向我们反馈意见。」

DeepSeek 表示,「在新的价格政策下,开发者调用 DeepSeek API 的成本将降低 50% 以上。目前 API 的模型版本为 DeepSeek-V3.2-Exp,访问方式保持不变。」

仅仅 4 分钟后,即 18:11,寒武纪旗下的微信公众号 「寒武纪开发者」 发布文章称:「2025 年 9 月 29 日,寒武纪已同步实现对深度求索公司最新模型 DeepSeek-V3.2-Exp 的适配,并开源大模型推理引擎 vLLM-MLU 源代码。代码地址和测试步骤见文末,开发者可以在寒武纪软硬件平台上第一时间体验 DeepSeek-V3.2-Exp 的亮点。」
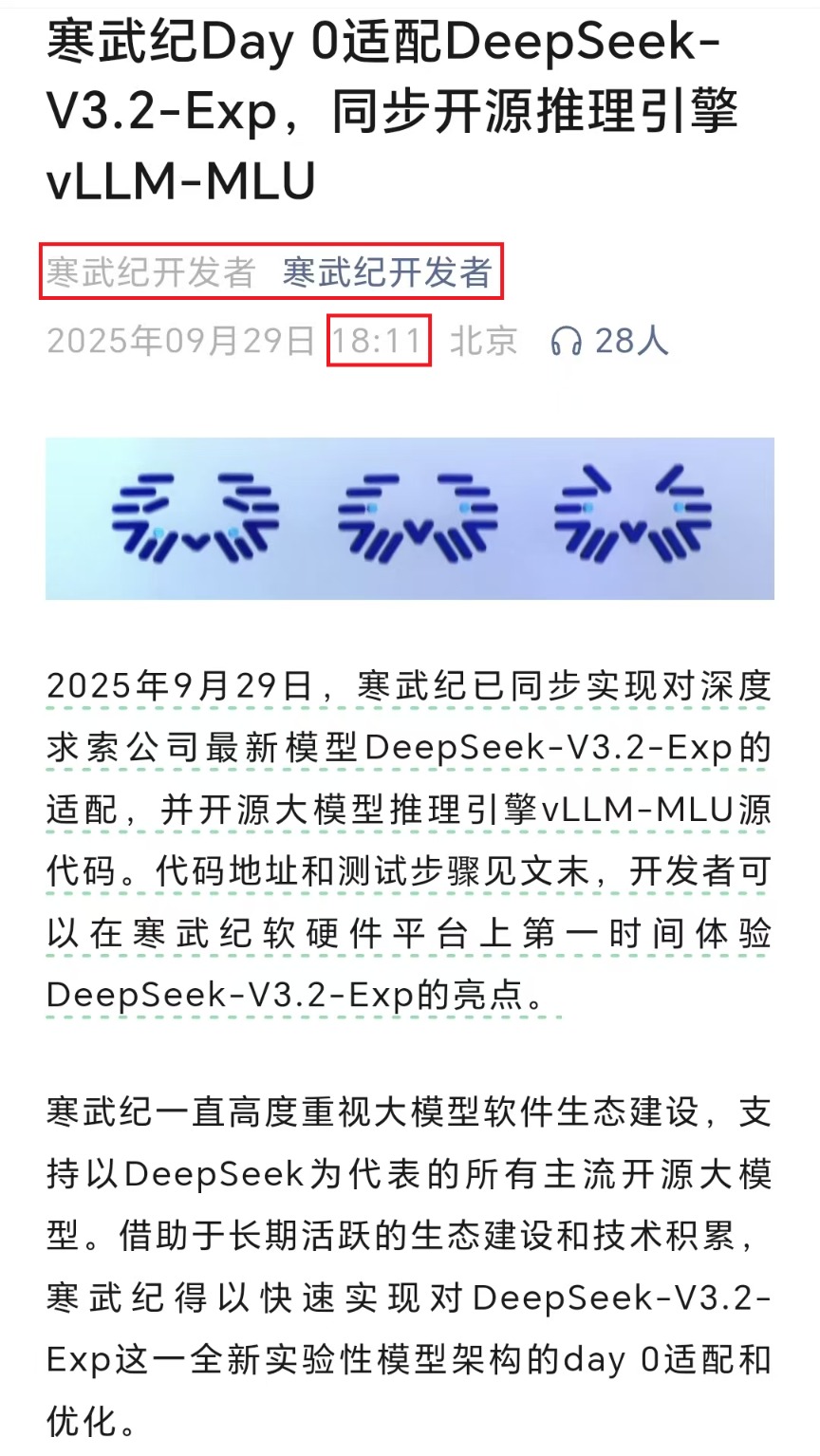
寒武纪表示,公司一直高度重视大模型软件生态建设,支持以 DeepSeek 为代表的所有主流开源大模型。借助长期活跃的生态建设和技术积累,寒武纪得以快速实现对 DeepSeek-V3.2-Exp 这一全新实验性模型架构的 day 0 适配和优化。
寒武纪称,公司一直重视芯片和算法的联合创新,致力于以软硬件协同的方式,优化大模型部署性能,降低部署成本。
此前,寒武纪对 DeepSeek 系列模型进行了深入的软硬件协同性能优化,达成了业界领先的算力利用率水平。针对本次的 DeepSeek-V3.2-Exp 新模型架构,寒武纪通过 Triton 算子开发实现了快速适配,利用 BangC 融合算子开发实现了极致性能优化,并基于计算与通信的并行策略,再次达成了业界领先的计算效率水平。
「依托 DeepSeek-V3.2-Exp 带来的全新 DeepSeek Sparse Attention 机制,叠加寒武纪的极致计算效率,可大幅降低长序列场景下的训推成本,共同为客户提供极具竞争力的软硬件解决方案。」 寒武纪强调。
在业内人士看来,此种同步发布适配的动作,表明中国 AI 产业链头部公司正在进行深度协同。这表明,或许早在 DeepSeek-V3.2 发布之前,寒武纪就在技术方面与 DeepSeek 进行沟通,并启动相关适配研发工作。
(中国基金报)
文章转载自东方财富
