

【文章来源:techweb】
【TechWeb】11 月 10 日消息,「这是又一次 DeepSeek 式的辉煌时刻吗?开源软件再次超越闭源软件。」 国际知名开源平台 Hugging Face 联合创始人 Thomas Wolf 在社交媒体上这样评价 Kimi K2 Thinking 的发布。
11 月 6 日,中国 AI 初创公司月之暗面 (Moonshot AI) 推出并开源了其最新生成式人工智能模型——Kimi K2 Thinking。这款模型在多项核心基准测试中超越了 OpenAI 的 GPT-5 和 Anthropic 的 Claude Sonnet 4.5。
而更令人震惊的是,媒体援引据一位知情人士透露,Kimi K2 Thinking 模型的训练成本为 460 万美元,这一数字不到 GPT-3 训练成本的百分之一。
开源大模型正在全球 AI 领域掀起一场效率革命与成本风暴,而这场风暴的中心,正逐渐转向东方。
训练成本仅 460 万美元?小成本模型实现大性能突破
Kimi K2 Thinking 的出现,彻底刷新了业界对 AI 模型成本与性能的认知。这个拥有 1 万亿参数的混合专家模型,每次推理仅激活 320 亿参数。
在技术设计上,它完美平衡了模型规模与计算效率,支持 256k 的上下文窗口,并采用原生 INT4 量化技术。

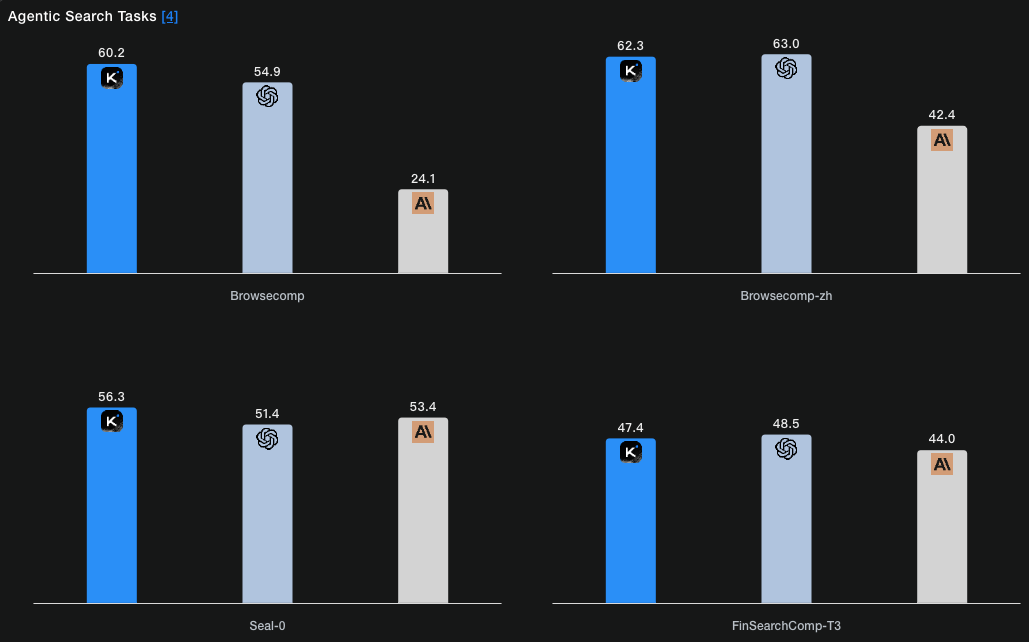
在权威基准测试中,Kimi K2 Thinking 展现出了令人瞩目的实力:在 Humanity『s Last Exam 中取得 44.9% 的优异成绩,在 BrowseComp 测试中获得 60.2%,在 SWE-Bench Verified 和 LiveCodeBench v6 两个编码评估中分别达到 71.3% 和 83.1%。

Kimi K2 Thinking 模型的核心优势之一是它的 Agent 能力,能够连续执行 200-300 次工具调用,无需人工干预即可解决复杂问题。
在编程实践中,开发者只需一句指令,就能生成一个类似 Mac OS 的网页操作系统,具备文本编辑器、文件管理器、画图工具等完整功能。
如果说性能表现令人赞叹,那么 Kimi K2 Thinking 的成本控制则堪称革命。460 万美元的训练成本,放在动辄数亿美元投入的大模型赛道,几乎是一个可以忽略不计的数字。
这一数字甚至低于 DeepSeek V3 模型的 560 万美元,更是与 GPT-3 等国际同类大模型高达数十亿美元的训练投入形成鲜明对比。
低成本的训练并未牺牲性能,Kimi K2 Thinking 在保持顶尖性能的同时,运行成本也大幅降低。
Kimi K2 Thinking 团队介绍,这种成本优势源于多方面的技术创新。一方面,模型采用了改进的 MuonClip 优化器,在长达 15.5 万亿 tokens 的预训练过程中实现了 「零损失尖峰」 ,意味着训练过程极其稳定。
另一方面,原生 INT4 量化技术不仅将推理速度提升了约 2 倍,还显著降低了部署所需的 GPU 显存,使模型对硬件更加友好。
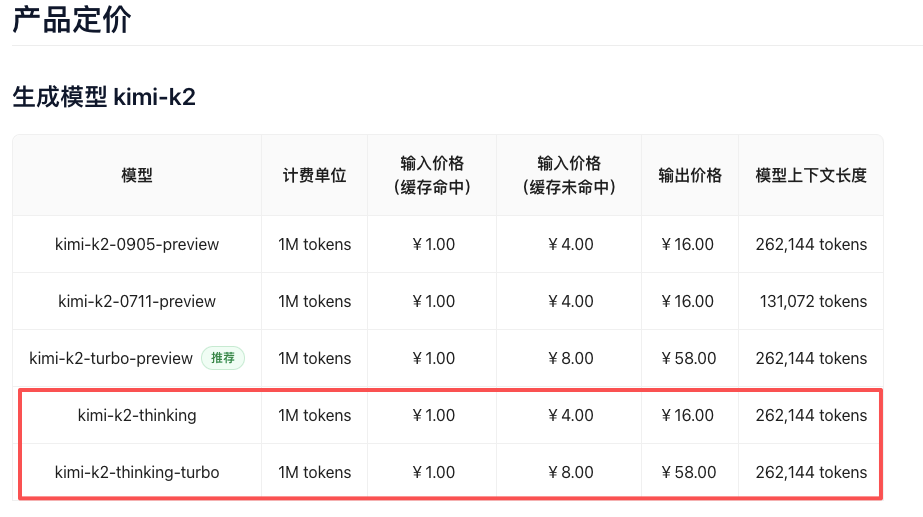
Kimi K2 Thinking 的 API 调用价格为每百万 token 输入 1 元 (缓存命中)/4 元 (缓存未命中),输出为每百万 token 16 元,相比 GPT-5 低一个数量级。
月之暗面 2025 年 7 月 11 日发布初代 Kimi K2 模型;9 月 5 日升级为 Kimi K2-0905 版本,强化 Agentic Coding 能力;11 月 6 日发布 Kimi-k2 thinking
以至于,有国外 AI 发烧友在 X 上直接 @了 OpenAl 的 CEO 奧特曼抛出了一个极其尖锐的问题:「你 (Sam) 凭什么需要数万亿美元才能做出顶尖模型而现在来自中国的模型,只花了区区 460 万美元就已经做得和你一样好,甚至更好? 这到底是为什么?」
有网友评论:这个问题,简直是把所有的硅谷 AI 巨头们架在火上烤。它用一种无可辩驳的方式证明了:更聪明的算法、更专注的团队以及站在巨人 (开源社区) 的肩膀上,完全可以以小博大。
同时,Kimi 也升级了 C 端的会员计划。

规则改写:开源协议的反向输出
Kimi K2 Thinking 的发布,迅速引发了全球 AI 社区的强烈反响。Hugging Face 联合创始人 Thomas Wolf 的评价绝非个例,来自各方的反馈都肯定了这款模型的重要意义。
业内普遍认为,Kimi K2 Thinking 极大地缩小了开源模型与闭源模型之间的差距,甚至在多个关键领域实现了反超。
开源的、可自由使用和修改的模型,首次在推理、编程和 Agent 能力等多个维度与顶尖闭源模型站在同一水平线上。
开发者社区对模型的实际表现给予了积极评价。有开发者测试后表示,Kimi K2 Thinking 在创意写作方面表现出色,能够 「将粗略的灵感转化为清晰、动人且意图明确的叙述」。
同时,其在处理复杂编程任务时展现出的逻辑性和完整性也令人印象深刻。
Kimi K2 Thinking 引发广泛讨论的,不仅是其技术实力,还有其独特的开源规则。
模型采用 Modified MIT 许可证,在保留标准 MIT 许可证绝大多数自由的基础上,添加了一项关键限制:「如果此模型被用于超过一亿月活用户,或者 2000 万美元月收入的商业产品中,需要注明商品底层使用了 Kimi K2 模型」。
有美国的科技博主表示,Kimi K2 为防止美国一些公司继续白剽这些开源模型并套牌说是自己的,出现了比较 「奇怪」 的 modifiedMIT License,并感叹:「世界颠倒了,这可不好」。
这一条款为开源软件协议带来了新思路。对于绝大多数研究机构和企业应用,这只是一项轻量级的 attribution 要求,不影响商业使用和衍生开发。
但当项目规模达到巨头级别时,仍需保留对原始开发者的尊重和认可。
这种规则设计,可视为中国 AI 企业首次在开源协议中引入如此影响力的条款,开创了开源规则 「反向输出」 的先例。
长期以来,中国科技企业更多是国际开源规则的接受者,而 Kimi K2 Thinking 的开源协议标志着这一格局正在改变。
以小博大,重塑 AI 竞争格局
DeepSeek-R1 和 Kimi K2 Thinking 这类小成本模型的崛起,正在从根本上改变全球大模型行业的竞争规则和未来走向。
这些模型证明了,通过架构创新和工程优化,完全可以在控制成本的同时实现顶尖性能。
传统的 「规模至上」 的发展模式遭到挑战。过去,OpenAI 及美国 AI 公司的核心护城河之一是强大的融资能力和大规模算力基础。
而今,一个依赖数十亿美元投入、指望高价 API 收回成本的商业模式,突然要面对一个性能接近、但 API 成本低 10 倍的竞争者。
猎豹移动 CEO 傅盛的评价就指出 Kimi K2 Thinking 的真正价值:「Kimi 真正 『可怕』 的地方不是性能的绝对超越,而是来自其极不对称的性价比。」
他强调,当一个开源模型以极低的训练成本达到了最先进模型 90% 的纸面能力和 75% 的实际能力时,整个战局有彻底改变的可能。
行业已告别 「比参数、比算力」 的粗放阶段,进入 「比落地、比价值」 的精耕时代。企业应用不再盲目追求模型的 「大而全」,而是更关注 「刚刚好」 的智能——在成本、速度和隐私间找到平衡点。
更为深远的是,小成本模型可能成为中国在全球 AI 竞赛中的差异化路径。
没有人会再质疑——开源模型的 「星星之火,可以燎原」。
【文章来源:techweb】
【TechWeb】11 月 10 日消息,「这是又一次 DeepSeek 式的辉煌时刻吗?开源软件再次超越闭源软件。」 国际知名开源平台 Hugging Face 联合创始人 Thomas Wolf 在社交媒体上这样评价 Kimi K2 Thinking 的发布。
11 月 6 日,中国 AI 初创公司月之暗面 (Moonshot AI) 推出并开源了其最新生成式人工智能模型——Kimi K2 Thinking。这款模型在多项核心基准测试中超越了 OpenAI 的 GPT-5 和 Anthropic 的 Claude Sonnet 4.5。
而更令人震惊的是,媒体援引据一位知情人士透露,Kimi K2 Thinking 模型的训练成本为 460 万美元,这一数字不到 GPT-3 训练成本的百分之一。
开源大模型正在全球 AI 领域掀起一场效率革命与成本风暴,而这场风暴的中心,正逐渐转向东方。
训练成本仅 460 万美元?小成本模型实现大性能突破
Kimi K2 Thinking 的出现,彻底刷新了业界对 AI 模型成本与性能的认知。这个拥有 1 万亿参数的混合专家模型,每次推理仅激活 320 亿参数。
在技术设计上,它完美平衡了模型规模与计算效率,支持 256k 的上下文窗口,并采用原生 INT4 量化技术。
在权威基准测试中,Kimi K2 Thinking 展现出了令人瞩目的实力:在 Humanity『s Last Exam 中取得 44.9% 的优异成绩,在 BrowseComp 测试中获得 60.2%,在 SWE-Bench Verified 和 LiveCodeBench v6 两个编码评估中分别达到 71.3% 和 83.1%。
Kimi K2 Thinking 模型的核心优势之一是它的 Agent 能力,能够连续执行 200-300 次工具调用,无需人工干预即可解决复杂问题。
在编程实践中,开发者只需一句指令,就能生成一个类似 Mac OS 的网页操作系统,具备文本编辑器、文件管理器、画图工具等完整功能。
如果说性能表现令人赞叹,那么 Kimi K2 Thinking 的成本控制则堪称革命。460 万美元的训练成本,放在动辄数亿美元投入的大模型赛道,几乎是一个可以忽略不计的数字。
这一数字甚至低于 DeepSeek V3 模型的 560 万美元,更是与 GPT-3 等国际同类大模型高达数十亿美元的训练投入形成鲜明对比。
低成本的训练并未牺牲性能,Kimi K2 Thinking 在保持顶尖性能的同时,运行成本也大幅降低。
Kimi K2 Thinking 团队介绍,这种成本优势源于多方面的技术创新。一方面,模型采用了改进的 MuonClip 优化器,在长达 15.5 万亿 tokens 的预训练过程中实现了 「零损失尖峰」 ,意味着训练过程极其稳定。
另一方面,原生 INT4 量化技术不仅将推理速度提升了约 2 倍,还显著降低了部署所需的 GPU 显存,使模型对硬件更加友好。
Kimi K2 Thinking 的 API 调用价格为每百万 token 输入 1 元 (缓存命中)/4 元 (缓存未命中),输出为每百万 token 16 元,相比 GPT-5 低一个数量级。
月之暗面 2025 年 7 月 11 日发布初代 Kimi K2 模型;9 月 5 日升级为 Kimi K2-0905 版本,强化 Agentic Coding 能力;11 月 6 日发布 Kimi-k2 thinking
以至于,有国外 AI 发烧友在 X 上直接 @了 OpenAl 的 CEO 奧特曼抛出了一个极其尖锐的问题:「你 (Sam) 凭什么需要数万亿美元才能做出顶尖模型而现在来自中国的模型,只花了区区 460 万美元就已经做得和你一样好,甚至更好? 这到底是为什么?」
有网友评论:这个问题,简直是把所有的硅谷 AI 巨头们架在火上烤。它用一种无可辩驳的方式证明了:更聪明的算法、更专注的团队以及站在巨人 (开源社区) 的肩膀上,完全可以以小博大。
同时,Kimi 也升级了 C 端的会员计划。
规则改写:开源协议的反向输出
Kimi K2 Thinking 的发布,迅速引发了全球 AI 社区的强烈反响。Hugging Face 联合创始人 Thomas Wolf 的评价绝非个例,来自各方的反馈都肯定了这款模型的重要意义。
业内普遍认为,Kimi K2 Thinking 极大地缩小了开源模型与闭源模型之间的差距,甚至在多个关键领域实现了反超。
开源的、可自由使用和修改的模型,首次在推理、编程和 Agent 能力等多个维度与顶尖闭源模型站在同一水平线上。
开发者社区对模型的实际表现给予了积极评价。有开发者测试后表示,Kimi K2 Thinking 在创意写作方面表现出色,能够 「将粗略的灵感转化为清晰、动人且意图明确的叙述」。
同时,其在处理复杂编程任务时展现出的逻辑性和完整性也令人印象深刻。
Kimi K2 Thinking 引发广泛讨论的,不仅是其技术实力,还有其独特的开源规则。
模型采用 Modified MIT 许可证,在保留标准 MIT 许可证绝大多数自由的基础上,添加了一项关键限制:「如果此模型被用于超过一亿月活用户,或者 2000 万美元月收入的商业产品中,需要注明商品底层使用了 Kimi K2 模型」。
有美国的科技博主表示,Kimi K2 为防止美国一些公司继续白剽这些开源模型并套牌说是自己的,出现了比较 「奇怪」 的 modifiedMIT License,并感叹:「世界颠倒了,这可不好」。
这一条款为开源软件协议带来了新思路。对于绝大多数研究机构和企业应用,这只是一项轻量级的 attribution 要求,不影响商业使用和衍生开发。
但当项目规模达到巨头级别时,仍需保留对原始开发者的尊重和认可。
这种规则设计,可视为中国 AI 企业首次在开源协议中引入如此影响力的条款,开创了开源规则 「反向输出」 的先例。
长期以来,中国科技企业更多是国际开源规则的接受者,而 Kimi K2 Thinking 的开源协议标志着这一格局正在改变。
以小博大,重塑 AI 竞争格局
DeepSeek-R1 和 Kimi K2 Thinking 这类小成本模型的崛起,正在从根本上改变全球大模型行业的竞争规则和未来走向。
这些模型证明了,通过架构创新和工程优化,完全可以在控制成本的同时实现顶尖性能。
传统的 「规模至上」 的发展模式遭到挑战。过去,OpenAI 及美国 AI 公司的核心护城河之一是强大的融资能力和大规模算力基础。
而今,一个依赖数十亿美元投入、指望高价 API 收回成本的商业模式,突然要面对一个性能接近、但 API 成本低 10 倍的竞争者。
猎豹移动 CEO 傅盛的评价就指出 Kimi K2 Thinking 的真正价值:「Kimi 真正 『可怕』 的地方不是性能的绝对超越,而是来自其极不对称的性价比。」
他强调,当一个开源模型以极低的训练成本达到了最先进模型 90% 的纸面能力和 75% 的实际能力时,整个战局有彻底改变的可能。
行业已告别 「比参数、比算力」 的粗放阶段,进入 「比落地、比价值」 的精耕时代。企业应用不再盲目追求模型的 「大而全」,而是更关注 「刚刚好」 的智能——在成本、速度和隐私间找到平衡点。
更为深远的是,小成本模型可能成为中国在全球 AI 竞赛中的差异化路径。
没有人会再质疑——开源模型的 「星星之火,可以燎原」。
【文章来源:techweb】
【TechWeb】11 月 10 日消息,「这是又一次 DeepSeek 式的辉煌时刻吗?开源软件再次超越闭源软件。」 国际知名开源平台 Hugging Face 联合创始人 Thomas Wolf 在社交媒体上这样评价 Kimi K2 Thinking 的发布。
11 月 6 日,中国 AI 初创公司月之暗面 (Moonshot AI) 推出并开源了其最新生成式人工智能模型——Kimi K2 Thinking。这款模型在多项核心基准测试中超越了 OpenAI 的 GPT-5 和 Anthropic 的 Claude Sonnet 4.5。
而更令人震惊的是,媒体援引据一位知情人士透露,Kimi K2 Thinking 模型的训练成本为 460 万美元,这一数字不到 GPT-3 训练成本的百分之一。
开源大模型正在全球 AI 领域掀起一场效率革命与成本风暴,而这场风暴的中心,正逐渐转向东方。
训练成本仅 460 万美元?小成本模型实现大性能突破
Kimi K2 Thinking 的出现,彻底刷新了业界对 AI 模型成本与性能的认知。这个拥有 1 万亿参数的混合专家模型,每次推理仅激活 320 亿参数。
在技术设计上,它完美平衡了模型规模与计算效率,支持 256k 的上下文窗口,并采用原生 INT4 量化技术。
在权威基准测试中,Kimi K2 Thinking 展现出了令人瞩目的实力:在 Humanity『s Last Exam 中取得 44.9% 的优异成绩,在 BrowseComp 测试中获得 60.2%,在 SWE-Bench Verified 和 LiveCodeBench v6 两个编码评估中分别达到 71.3% 和 83.1%。
Kimi K2 Thinking 模型的核心优势之一是它的 Agent 能力,能够连续执行 200-300 次工具调用,无需人工干预即可解决复杂问题。
在编程实践中,开发者只需一句指令,就能生成一个类似 Mac OS 的网页操作系统,具备文本编辑器、文件管理器、画图工具等完整功能。
如果说性能表现令人赞叹,那么 Kimi K2 Thinking 的成本控制则堪称革命。460 万美元的训练成本,放在动辄数亿美元投入的大模型赛道,几乎是一个可以忽略不计的数字。
这一数字甚至低于 DeepSeek V3 模型的 560 万美元,更是与 GPT-3 等国际同类大模型高达数十亿美元的训练投入形成鲜明对比。
低成本的训练并未牺牲性能,Kimi K2 Thinking 在保持顶尖性能的同时,运行成本也大幅降低。
Kimi K2 Thinking 团队介绍,这种成本优势源于多方面的技术创新。一方面,模型采用了改进的 MuonClip 优化器,在长达 15.5 万亿 tokens 的预训练过程中实现了 「零损失尖峰」 ,意味着训练过程极其稳定。
另一方面,原生 INT4 量化技术不仅将推理速度提升了约 2 倍,还显著降低了部署所需的 GPU 显存,使模型对硬件更加友好。
Kimi K2 Thinking 的 API 调用价格为每百万 token 输入 1 元 (缓存命中)/4 元 (缓存未命中),输出为每百万 token 16 元,相比 GPT-5 低一个数量级。
月之暗面 2025 年 7 月 11 日发布初代 Kimi K2 模型;9 月 5 日升级为 Kimi K2-0905 版本,强化 Agentic Coding 能力;11 月 6 日发布 Kimi-k2 thinking
以至于,有国外 AI 发烧友在 X 上直接 @了 OpenAl 的 CEO 奧特曼抛出了一个极其尖锐的问题:「你 (Sam) 凭什么需要数万亿美元才能做出顶尖模型而现在来自中国的模型,只花了区区 460 万美元就已经做得和你一样好,甚至更好? 这到底是为什么?」
有网友评论:这个问题,简直是把所有的硅谷 AI 巨头们架在火上烤。它用一种无可辩驳的方式证明了:更聪明的算法、更专注的团队以及站在巨人 (开源社区) 的肩膀上,完全可以以小博大。
同时,Kimi 也升级了 C 端的会员计划。
规则改写:开源协议的反向输出
Kimi K2 Thinking 的发布,迅速引发了全球 AI 社区的强烈反响。Hugging Face 联合创始人 Thomas Wolf 的评价绝非个例,来自各方的反馈都肯定了这款模型的重要意义。
业内普遍认为,Kimi K2 Thinking 极大地缩小了开源模型与闭源模型之间的差距,甚至在多个关键领域实现了反超。
开源的、可自由使用和修改的模型,首次在推理、编程和 Agent 能力等多个维度与顶尖闭源模型站在同一水平线上。
开发者社区对模型的实际表现给予了积极评价。有开发者测试后表示,Kimi K2 Thinking 在创意写作方面表现出色,能够 「将粗略的灵感转化为清晰、动人且意图明确的叙述」。
同时,其在处理复杂编程任务时展现出的逻辑性和完整性也令人印象深刻。
Kimi K2 Thinking 引发广泛讨论的,不仅是其技术实力,还有其独特的开源规则。
模型采用 Modified MIT 许可证,在保留标准 MIT 许可证绝大多数自由的基础上,添加了一项关键限制:「如果此模型被用于超过一亿月活用户,或者 2000 万美元月收入的商业产品中,需要注明商品底层使用了 Kimi K2 模型」。
有美国的科技博主表示,Kimi K2 为防止美国一些公司继续白剽这些开源模型并套牌说是自己的,出现了比较 「奇怪」 的 modifiedMIT License,并感叹:「世界颠倒了,这可不好」。
这一条款为开源软件协议带来了新思路。对于绝大多数研究机构和企业应用,这只是一项轻量级的 attribution 要求,不影响商业使用和衍生开发。
但当项目规模达到巨头级别时,仍需保留对原始开发者的尊重和认可。
这种规则设计,可视为中国 AI 企业首次在开源协议中引入如此影响力的条款,开创了开源规则 「反向输出」 的先例。
长期以来,中国科技企业更多是国际开源规则的接受者,而 Kimi K2 Thinking 的开源协议标志着这一格局正在改变。
以小博大,重塑 AI 竞争格局
DeepSeek-R1 和 Kimi K2 Thinking 这类小成本模型的崛起,正在从根本上改变全球大模型行业的竞争规则和未来走向。
这些模型证明了,通过架构创新和工程优化,完全可以在控制成本的同时实现顶尖性能。
传统的 「规模至上」 的发展模式遭到挑战。过去,OpenAI 及美国 AI 公司的核心护城河之一是强大的融资能力和大规模算力基础。
而今,一个依赖数十亿美元投入、指望高价 API 收回成本的商业模式,突然要面对一个性能接近、但 API 成本低 10 倍的竞争者。
猎豹移动 CEO 傅盛的评价就指出 Kimi K2 Thinking 的真正价值:「Kimi 真正 『可怕』 的地方不是性能的绝对超越,而是来自其极不对称的性价比。」
他强调,当一个开源模型以极低的训练成本达到了最先进模型 90% 的纸面能力和 75% 的实际能力时,整个战局有彻底改变的可能。
行业已告别 「比参数、比算力」 的粗放阶段,进入 「比落地、比价值」 的精耕时代。企业应用不再盲目追求模型的 「大而全」,而是更关注 「刚刚好」 的智能——在成本、速度和隐私间找到平衡点。
更为深远的是,小成本模型可能成为中国在全球 AI 竞赛中的差异化路径。
没有人会再质疑——开源模型的 「星星之火,可以燎原」。
【文章来源:techweb】
【TechWeb】11 月 10 日消息,「这是又一次 DeepSeek 式的辉煌时刻吗?开源软件再次超越闭源软件。」 国际知名开源平台 Hugging Face 联合创始人 Thomas Wolf 在社交媒体上这样评价 Kimi K2 Thinking 的发布。
11 月 6 日,中国 AI 初创公司月之暗面 (Moonshot AI) 推出并开源了其最新生成式人工智能模型——Kimi K2 Thinking。这款模型在多项核心基准测试中超越了 OpenAI 的 GPT-5 和 Anthropic 的 Claude Sonnet 4.5。
而更令人震惊的是,媒体援引据一位知情人士透露,Kimi K2 Thinking 模型的训练成本为 460 万美元,这一数字不到 GPT-3 训练成本的百分之一。
开源大模型正在全球 AI 领域掀起一场效率革命与成本风暴,而这场风暴的中心,正逐渐转向东方。
训练成本仅 460 万美元?小成本模型实现大性能突破
Kimi K2 Thinking 的出现,彻底刷新了业界对 AI 模型成本与性能的认知。这个拥有 1 万亿参数的混合专家模型,每次推理仅激活 320 亿参数。
在技术设计上,它完美平衡了模型规模与计算效率,支持 256k 的上下文窗口,并采用原生 INT4 量化技术。
在权威基准测试中,Kimi K2 Thinking 展现出了令人瞩目的实力:在 Humanity『s Last Exam 中取得 44.9% 的优异成绩,在 BrowseComp 测试中获得 60.2%,在 SWE-Bench Verified 和 LiveCodeBench v6 两个编码评估中分别达到 71.3% 和 83.1%。
Kimi K2 Thinking 模型的核心优势之一是它的 Agent 能力,能够连续执行 200-300 次工具调用,无需人工干预即可解决复杂问题。
在编程实践中,开发者只需一句指令,就能生成一个类似 Mac OS 的网页操作系统,具备文本编辑器、文件管理器、画图工具等完整功能。
如果说性能表现令人赞叹,那么 Kimi K2 Thinking 的成本控制则堪称革命。460 万美元的训练成本,放在动辄数亿美元投入的大模型赛道,几乎是一个可以忽略不计的数字。
这一数字甚至低于 DeepSeek V3 模型的 560 万美元,更是与 GPT-3 等国际同类大模型高达数十亿美元的训练投入形成鲜明对比。
低成本的训练并未牺牲性能,Kimi K2 Thinking 在保持顶尖性能的同时,运行成本也大幅降低。
Kimi K2 Thinking 团队介绍,这种成本优势源于多方面的技术创新。一方面,模型采用了改进的 MuonClip 优化器,在长达 15.5 万亿 tokens 的预训练过程中实现了 「零损失尖峰」 ,意味着训练过程极其稳定。
另一方面,原生 INT4 量化技术不仅将推理速度提升了约 2 倍,还显著降低了部署所需的 GPU 显存,使模型对硬件更加友好。
Kimi K2 Thinking 的 API 调用价格为每百万 token 输入 1 元 (缓存命中)/4 元 (缓存未命中),输出为每百万 token 16 元,相比 GPT-5 低一个数量级。
月之暗面 2025 年 7 月 11 日发布初代 Kimi K2 模型;9 月 5 日升级为 Kimi K2-0905 版本,强化 Agentic Coding 能力;11 月 6 日发布 Kimi-k2 thinking
以至于,有国外 AI 发烧友在 X 上直接 @了 OpenAl 的 CEO 奧特曼抛出了一个极其尖锐的问题:「你 (Sam) 凭什么需要数万亿美元才能做出顶尖模型而现在来自中国的模型,只花了区区 460 万美元就已经做得和你一样好,甚至更好? 这到底是为什么?」
有网友评论:这个问题,简直是把所有的硅谷 AI 巨头们架在火上烤。它用一种无可辩驳的方式证明了:更聪明的算法、更专注的团队以及站在巨人 (开源社区) 的肩膀上,完全可以以小博大。
同时,Kimi 也升级了 C 端的会员计划。
规则改写:开源协议的反向输出
Kimi K2 Thinking 的发布,迅速引发了全球 AI 社区的强烈反响。Hugging Face 联合创始人 Thomas Wolf 的评价绝非个例,来自各方的反馈都肯定了这款模型的重要意义。
业内普遍认为,Kimi K2 Thinking 极大地缩小了开源模型与闭源模型之间的差距,甚至在多个关键领域实现了反超。
开源的、可自由使用和修改的模型,首次在推理、编程和 Agent 能力等多个维度与顶尖闭源模型站在同一水平线上。
开发者社区对模型的实际表现给予了积极评价。有开发者测试后表示,Kimi K2 Thinking 在创意写作方面表现出色,能够 「将粗略的灵感转化为清晰、动人且意图明确的叙述」。
同时,其在处理复杂编程任务时展现出的逻辑性和完整性也令人印象深刻。
Kimi K2 Thinking 引发广泛讨论的,不仅是其技术实力,还有其独特的开源规则。
模型采用 Modified MIT 许可证,在保留标准 MIT 许可证绝大多数自由的基础上,添加了一项关键限制:「如果此模型被用于超过一亿月活用户,或者 2000 万美元月收入的商业产品中,需要注明商品底层使用了 Kimi K2 模型」。
有美国的科技博主表示,Kimi K2 为防止美国一些公司继续白剽这些开源模型并套牌说是自己的,出现了比较 「奇怪」 的 modifiedMIT License,并感叹:「世界颠倒了,这可不好」。
这一条款为开源软件协议带来了新思路。对于绝大多数研究机构和企业应用,这只是一项轻量级的 attribution 要求,不影响商业使用和衍生开发。
但当项目规模达到巨头级别时,仍需保留对原始开发者的尊重和认可。
这种规则设计,可视为中国 AI 企业首次在开源协议中引入如此影响力的条款,开创了开源规则 「反向输出」 的先例。
长期以来,中国科技企业更多是国际开源规则的接受者,而 Kimi K2 Thinking 的开源协议标志着这一格局正在改变。
以小博大,重塑 AI 竞争格局
DeepSeek-R1 和 Kimi K2 Thinking 这类小成本模型的崛起,正在从根本上改变全球大模型行业的竞争规则和未来走向。
这些模型证明了,通过架构创新和工程优化,完全可以在控制成本的同时实现顶尖性能。
传统的 「规模至上」 的发展模式遭到挑战。过去,OpenAI 及美国 AI 公司的核心护城河之一是强大的融资能力和大规模算力基础。
而今,一个依赖数十亿美元投入、指望高价 API 收回成本的商业模式,突然要面对一个性能接近、但 API 成本低 10 倍的竞争者。
猎豹移动 CEO 傅盛的评价就指出 Kimi K2 Thinking 的真正价值:「Kimi 真正 『可怕』 的地方不是性能的绝对超越,而是来自其极不对称的性价比。」
他强调,当一个开源模型以极低的训练成本达到了最先进模型 90% 的纸面能力和 75% 的实际能力时,整个战局有彻底改变的可能。
行业已告别 「比参数、比算力」 的粗放阶段,进入 「比落地、比价值」 的精耕时代。企业应用不再盲目追求模型的 「大而全」,而是更关注 「刚刚好」 的智能——在成本、速度和隐私间找到平衡点。
更为深远的是,小成本模型可能成为中国在全球 AI 竞赛中的差异化路径。
没有人会再质疑——开源模型的 「星星之火,可以燎原」。