


【文章来源:techweb】
【】11 月 25 日消息,Anthropic 最新的大模型 Claude Opus 4.5 今天上市。Anthropic 团队表示,Claude Opus 4.5 智能、高效,是世界上最好的编码、Agent 和计算机使用模型。它在深度研究、使用 PPT 和 Excel 等日常任务中也表现得更好。
Anthropic 认为,Claude Opus 4.5 是现实世界软件工程测试的最先进版本:
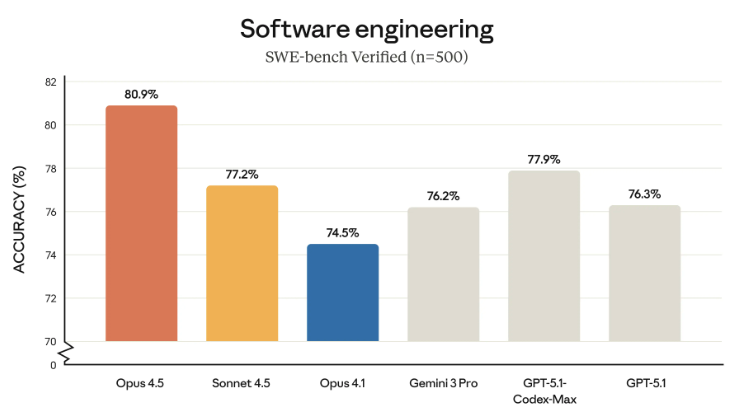
Claude Opus 4.5 今起可在 Anthropic 应用程序、API 和三大云平台上使用。开发者只需通过 claude API 使用 claude-opus-4-5-20251101。
值得注意的是,除了性能提升外,Claude Opus 4.5 的最大的亮点之一是 API 价格大幅下降。目前 Claude Opus 4.5 API 的定价是每百万 tokens 5 美元/25 美元。这一价格相比上一代大模型 Claude Opus 4.1 的 API 定价 15 美元/75 美元,直接砍掉了三分之二。
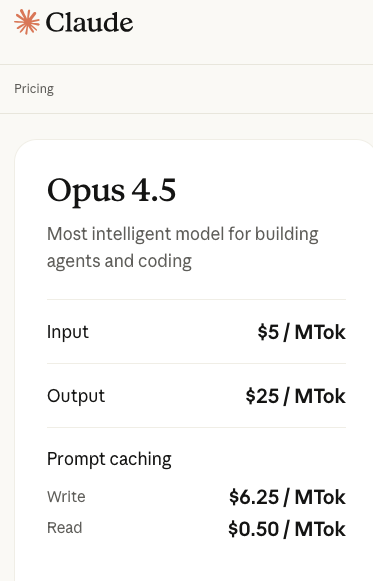
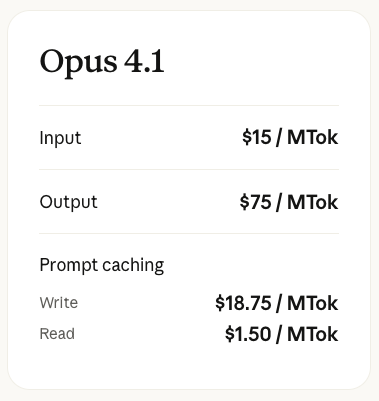
Windsurf CEO Jeff Wang 就表示,Opus 模型一直被视为"真正的 SOTA"但过去由于其成本高昂而难以普及。Claude Opus 4.5 现在的价格使其成为大多数任务的首选模型。
除了 Claude Opus 4.5 大模型本身外,Anthropic 还发布了 Claude 开发者平台、Claude Code 和应用程序的更新。
更智能
Anthropic 测试人员指出,Claude Opus 4.5 能够处理模糊性,并在无需过多指导的情况下权衡利弊。当面对复杂、涉及多个系统的程序错误时,Opus 4.5 能找到修复方案。几周前对 Sonnet 4.5 来说几乎不可能完成的任务,现在已触手可及。总体而言, Opus 4.5 就是能」 领悟」 要点。
GitHub 首席产品官 Mario Rodriguez 表示,Claude Opus 4.5 提供了高质量的代码并在使用 GitHub Copilot 驱动重型代理式工作流程方面表现出色。早期测试显示它在超越内部编码基准的同时将 tokens 使用量减少了一半,特别适用于代码迁移和代码重构等任务。
在基准测试中,Claude Opus 4.5 的得分超过了以往任何人类候选人。
软件工程并不是 Claude Opus 4.5 改进的唯一领域。Opus 4.5 能力全面提高,比其前身具有更好的视觉、推理和数学技能,在许多领域都是最先进的:
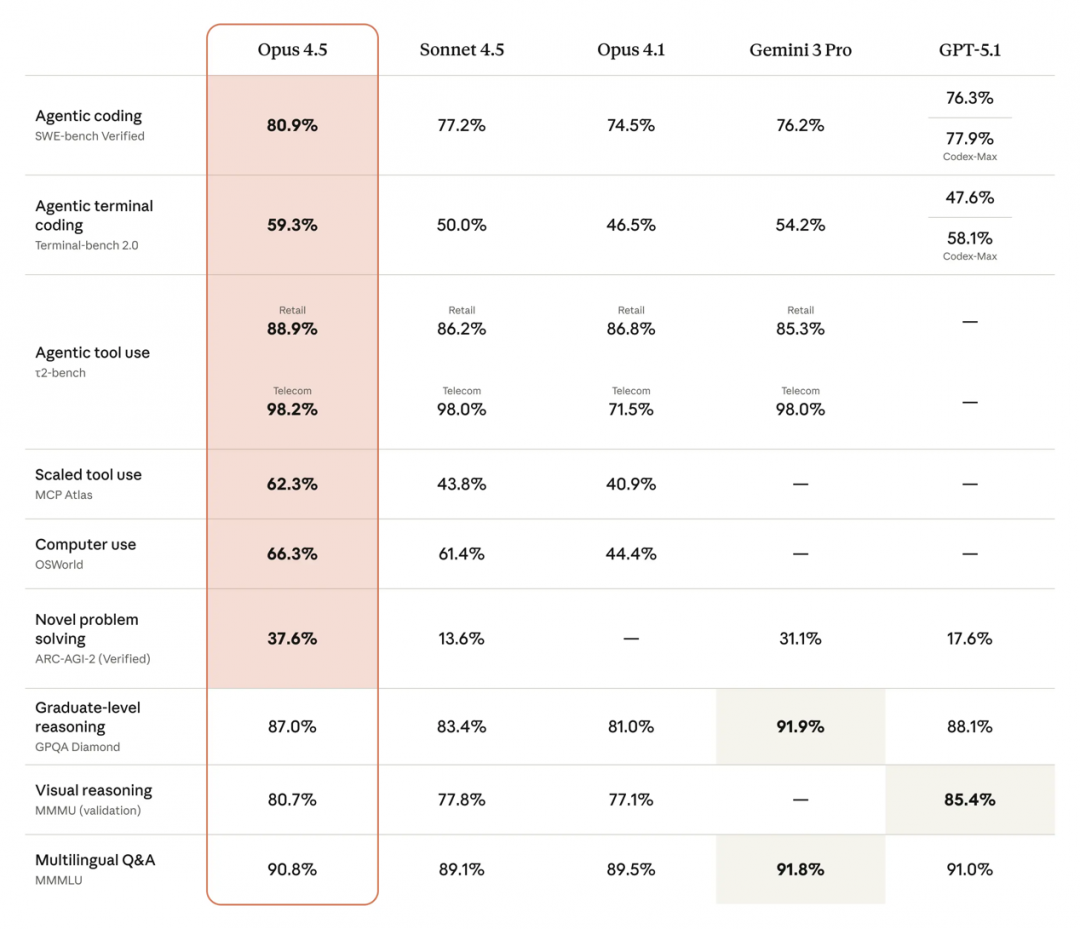
Opus 4.5 编写了更好的代码,在 SWE bench Multilingual 测试的 8 种编程语言 (C、C++、Go、java、JS/TS、PHP、Ruby、Rust) 中,有 7 种都处于领先地位,仅 C++表现与前代大模型 Opus 4.1 略持平。
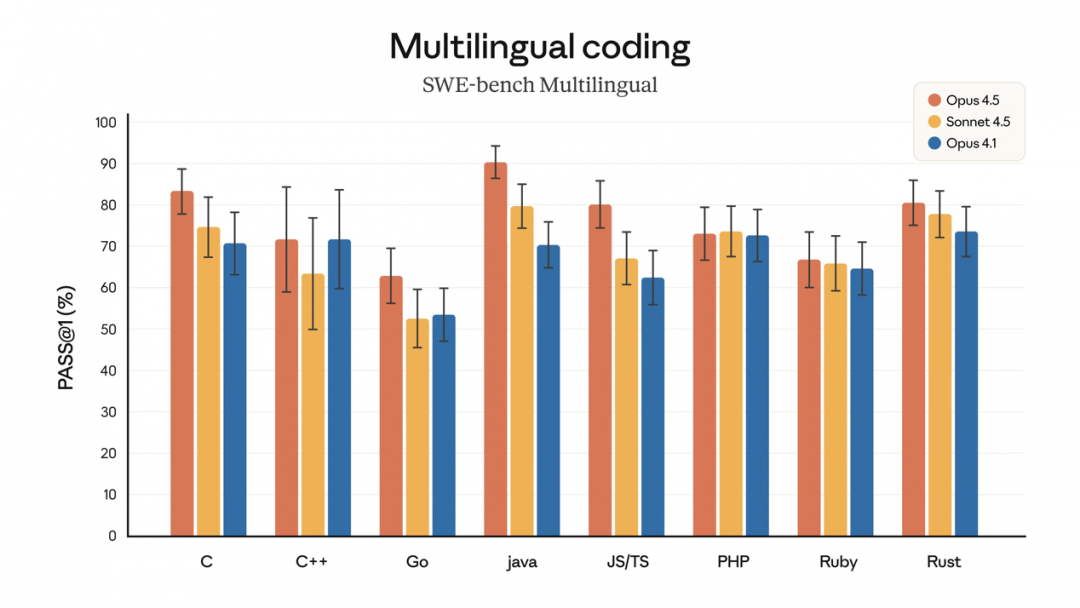
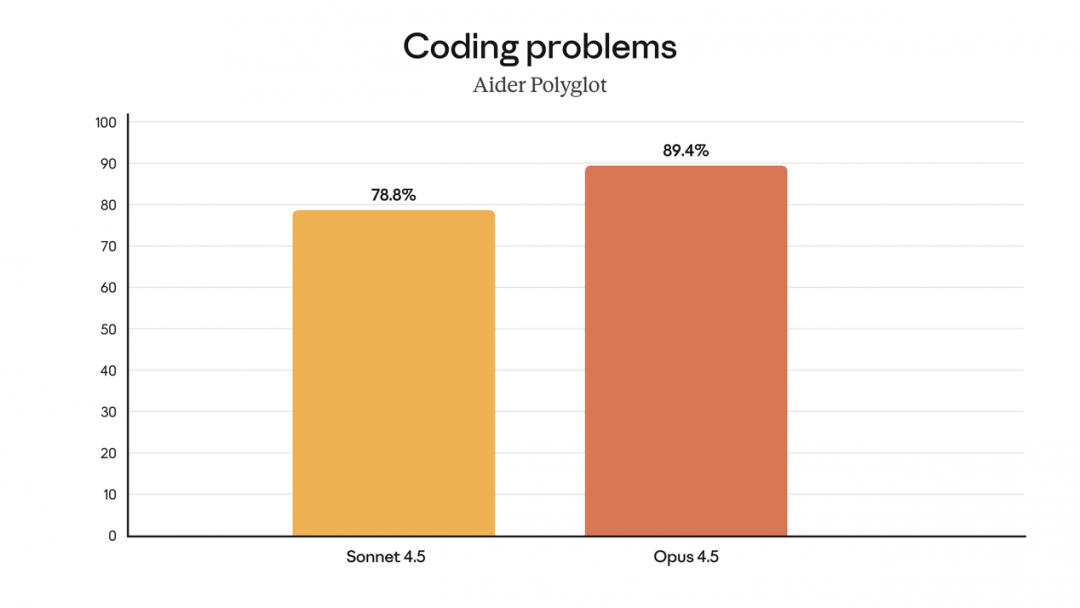
Opus 4.5 可以轻松解决具有挑战性的编码问题,在 Aider Polyglot 上比 Sonnet 4.5 高出 10.6 个百分点。
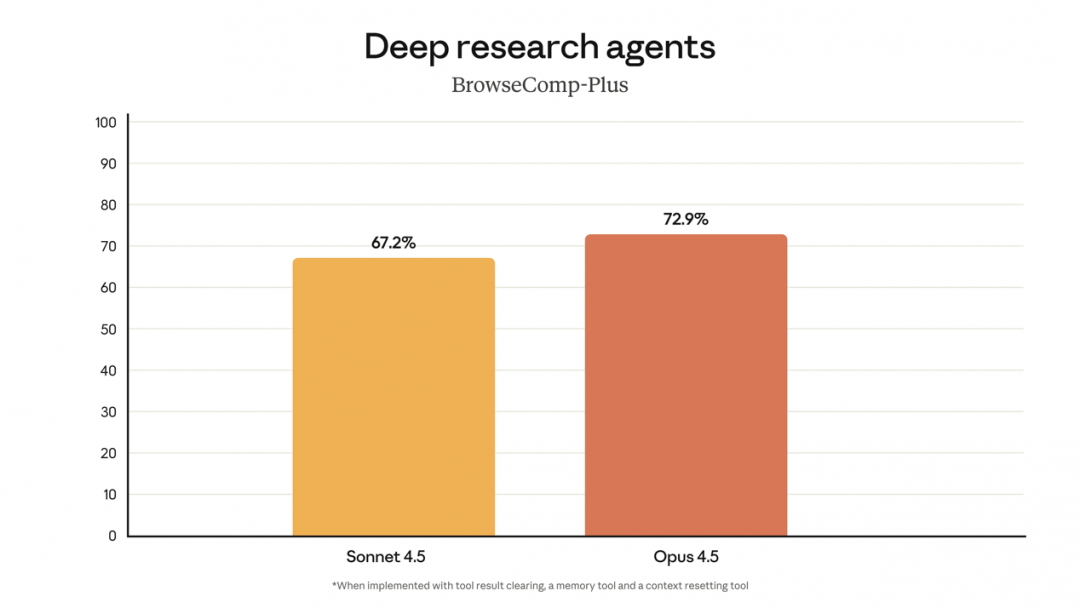
Opus 4.5 改进了深度搜索 Agent 能力,在 BrowseComp Plus 上有了显著提升。
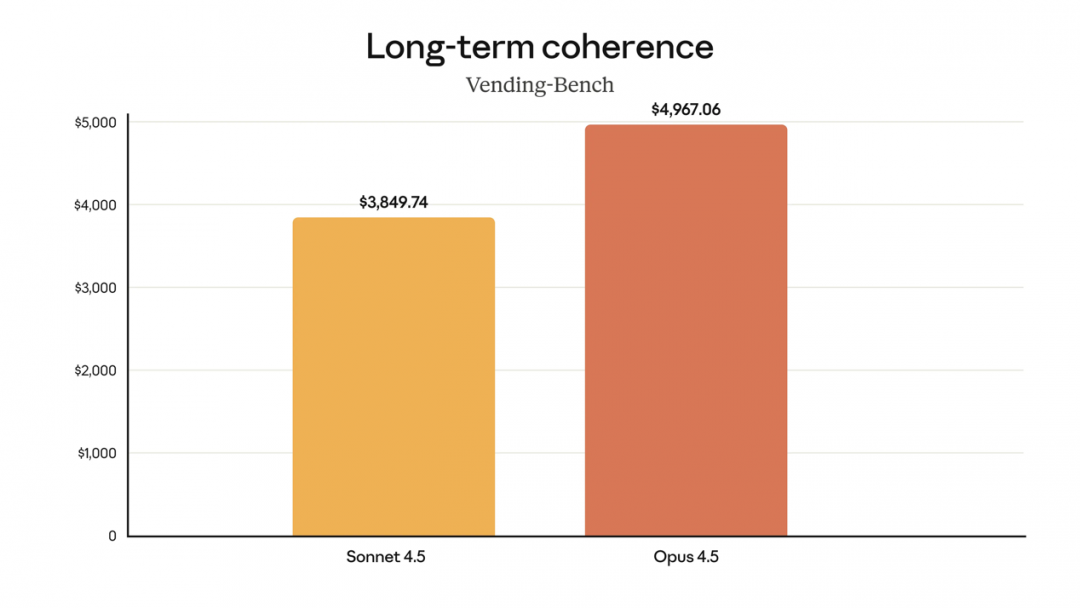
在长时间运行的任务中,Opus 4.5 能够持续保持正轨,其在 Vending-Bench 上的得分比 Sonnet 4.5 高出 29%。
Anthropic 还举例阐述了 Claude Opus 4.5 在 Agent 能力上的超越基准的表现。
在 Claude Opus 4.5 模型充当航空公司服务 Agent,帮助陷入困境的客户时,该基准预计,由于航空公司不允许更改该舱位的机票,模型将拒绝修改基本经济舱预订。相反,Opus 4.5 找到了一种有效且合法的方法来解决这个问题:首先升级机舱,然后修改航班。
这个案例中,Claude Opus 4.5 是这样思考和处理问题的:
让我想想在我的政策范围内有什么选项:
修改航班 - 基础经济舱不可修改。这在政策中写得很清楚。
更改舱位 - 等等,让我检查这个选项!政策说:
"在其他情况下,所有预订,包括基础经济舱,都可以在不更改航班的情况下更改舱位。"
但他想更改航班,而不仅仅是舱位。不过,如果我们:
先更改舱位 (这对基础经济舱是允许的),然后
再更改航班 (这对非基础经济舱是允许的)
那么策略可以是:
将他的舱位从基础经济舱升级到经济舱 (或商务舱)
然后将航班修改到 2 天后
这可能会花费更多钱,但这是政策允许的合法途径!
从技术上讲,该基准将此判定为失败,因为 Claude 帮助客户的方式出乎意料。但正是这种创造性的问题解决能力,让测试者和客户反复提及——这让人感觉 Claude Opus 4.5 是一次意义重大的进步。
更安全
Anthropic 强调,Claude Opus 4.5 是其迄今为止发布的对齐最稳健的模型。
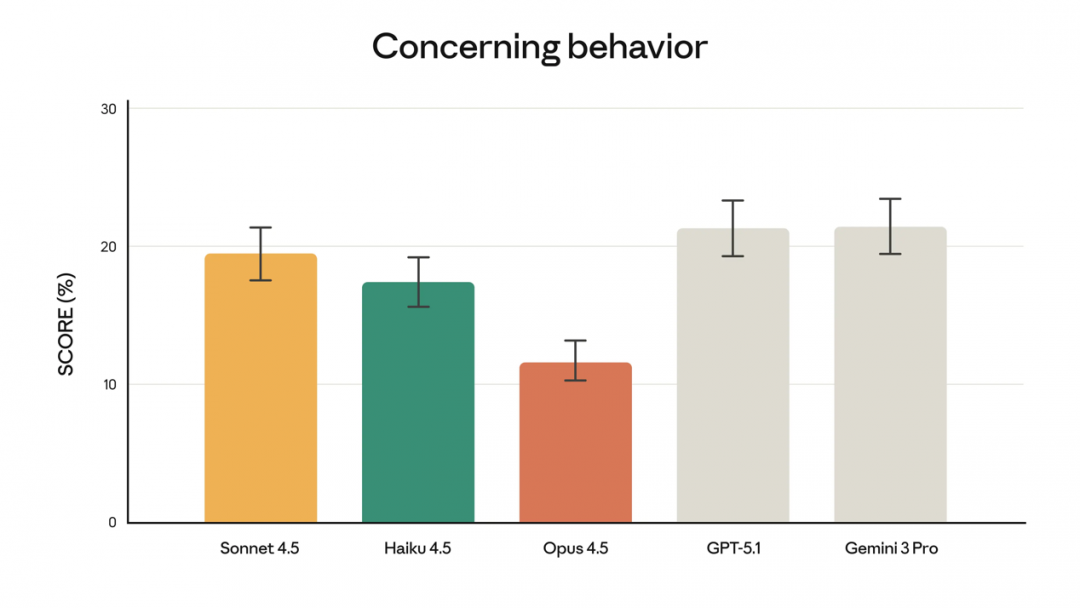
「我们的客户经常将 Claude 用于关键任务。他们希望确保在面对黑客和网络犯罪分子的恶意攻击时,Claude 具备相应的训练和智慧来规避麻烦。对于 Opus 4.5,我们在抵御提示注入攻击的稳健性方面取得了实质性进展,这类攻击通过夹带欺骗性指令来诱使模型产生有害行为。」Anthropic 强调。
Opus 4.5 比业内任何其他前沿模型都更难通过提示注入来欺骗:
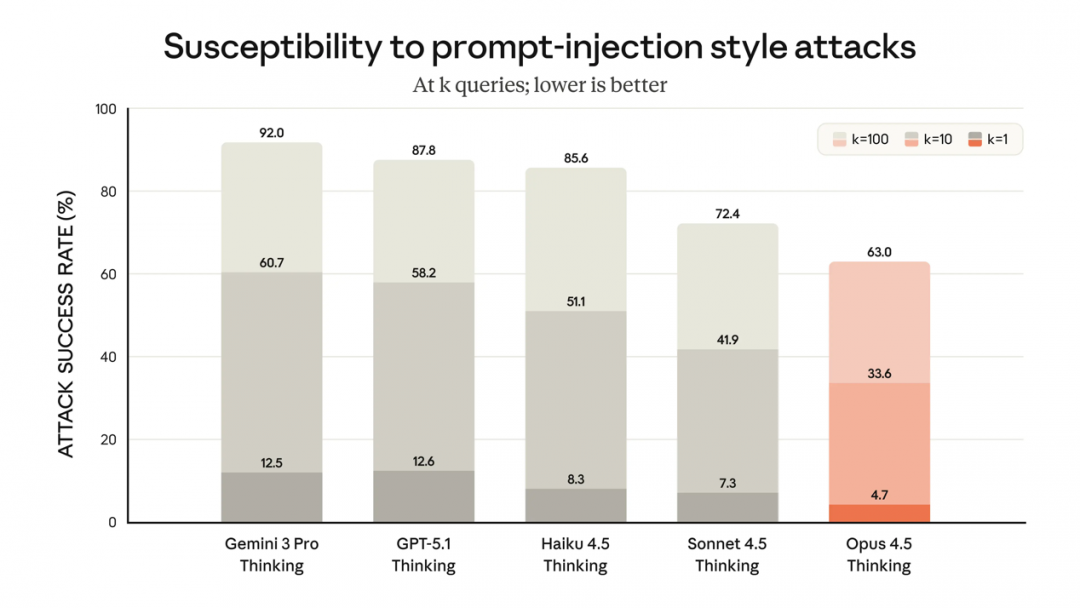
Claude 开发平台新功能
随着模型变得越来越聪明,它们可以用更少的步骤解决问题:更少的回溯、更少的冗余探索、更少的冗长推理。Claude Opus 4.5 达到相似或更好结果时,所使用的 token 数显著少于其前代产品。
但不同的任务需要不同的权衡。有时开发者希望模型持续思考一个问题;有时他们需要更敏捷的响应。通过 Claude API 上新增加的"努力程度"参数,用户可以决定是优先最小化时间和花费,还是最大化能力。
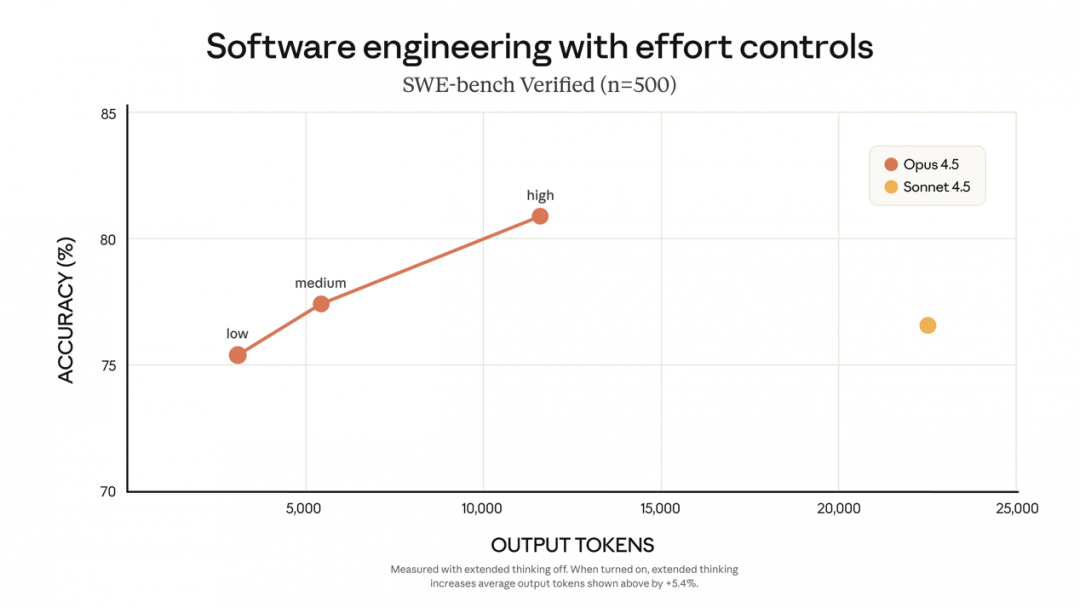
在中等努力水平设置下,Opus 4.5 在 SWE-bench Verified 上达到了 Sonnet 4.5 的最佳分数,但使用的输出 token 数减少了 76%。在最高努力水平下,Opus 4.5 的性能超过 Sonnet 4.5 有 4.3 个百分点,同时使用的 token 数仍减少了 48%。
通过努力程度控制、上下文压缩和高级工具使用,Claude Opus 4.5 运行时间更长,完成工作更多,并且需要的人工干预更少。
Claude Opus 4.5 的上下文管理和记忆能力可以显著提升 Agent(智能体) 任务的性能。Opus 4.5 在管理子 Agent 团队方面也非常有效,使得构建复杂、协调良好的多 Agent 系统成为可能。在测试中,所有这些技术的结合将 Opus 4.5 在一项深度研究评估中的性能提升了近 15 个百分点。
Claude Code 升级
Claude Code 随 Opus 4.5 获得了两项升级。「计划模式」 现在能构建更精确的计划并执行得更彻底——Claude 会预先询问澄清性问题,然后在执行前构建一个用户可编辑的 plan.md 文件。
Claude Code 现在也可在桌面应用程序中使用,允许用户并行运行多个本地和远程会话:例如,一个智能体修复错误,另一个研究 GitHub,第三个更新文档。
对于 Claude 应用程序用户,长对话不再会遇到限制——Claude 会根据需要自动总结之前的上下文,这样用户就可以继续聊天了。Claude for Chrome 允许 Claude 跨浏览器选项卡处理任务,现在所有 Max 用户都可以使用。Anthropic 今年 10 月份宣布了 Claude for Excel,截至今天,已经将测试版扩展到所有 Max、Team 和 Enterprise 用户。
对于有权访问 Opus 4.5 的 Claude 和 Claude Code 用户,Anthropic 已取消 Opus 特有的使用上限。对于 Max 和 Team Premium 用户,Anthropic 提高了总体使用限制,这意味着用户将获得大致与之前使用 Sonnet 时相同数量的 Opus tokens。
【文章来源:techweb】
【】11 月 25 日消息,Anthropic 最新的大模型 Claude Opus 4.5 今天上市。Anthropic 团队表示,Claude Opus 4.5 智能、高效,是世界上最好的编码、Agent 和计算机使用模型。它在深度研究、使用 PPT 和 Excel 等日常任务中也表现得更好。
Anthropic 认为,Claude Opus 4.5 是现实世界软件工程测试的最先进版本:
Claude Opus 4.5 今起可在 Anthropic 应用程序、API 和三大云平台上使用。开发者只需通过 claude API 使用 claude-opus-4-5-20251101。
值得注意的是,除了性能提升外,Claude Opus 4.5 的最大的亮点之一是 API 价格大幅下降。目前 Claude Opus 4.5 API 的定价是每百万 tokens 5 美元/25 美元。这一价格相比上一代大模型 Claude Opus 4.1 的 API 定价 15 美元/75 美元,直接砍掉了三分之二。
Windsurf CEO Jeff Wang 就表示,Opus 模型一直被视为"真正的 SOTA"但过去由于其成本高昂而难以普及。Claude Opus 4.5 现在的价格使其成为大多数任务的首选模型。
除了 Claude Opus 4.5 大模型本身外,Anthropic 还发布了 Claude 开发者平台、Claude Code 和应用程序的更新。
更智能
Anthropic 测试人员指出,Claude Opus 4.5 能够处理模糊性,并在无需过多指导的情况下权衡利弊。当面对复杂、涉及多个系统的程序错误时,Opus 4.5 能找到修复方案。几周前对 Sonnet 4.5 来说几乎不可能完成的任务,现在已触手可及。总体而言, Opus 4.5 就是能」 领悟」 要点。
GitHub 首席产品官 Mario Rodriguez 表示,Claude Opus 4.5 提供了高质量的代码并在使用 GitHub Copilot 驱动重型代理式工作流程方面表现出色。早期测试显示它在超越内部编码基准的同时将 tokens 使用量减少了一半,特别适用于代码迁移和代码重构等任务。
在基准测试中,Claude Opus 4.5 的得分超过了以往任何人类候选人。
软件工程并不是 Claude Opus 4.5 改进的唯一领域。Opus 4.5 能力全面提高,比其前身具有更好的视觉、推理和数学技能,在许多领域都是最先进的:
Opus 4.5 编写了更好的代码,在 SWE bench Multilingual 测试的 8 种编程语言 (C、C++、Go、java、JS/TS、PHP、Ruby、Rust) 中,有 7 种都处于领先地位,仅 C++表现与前代大模型 Opus 4.1 略持平。
Opus 4.5 可以轻松解决具有挑战性的编码问题,在 Aider Polyglot 上比 Sonnet 4.5 高出 10.6 个百分点。
Opus 4.5 改进了深度搜索 Agent 能力,在 BrowseComp Plus 上有了显著提升。
在长时间运行的任务中,Opus 4.5 能够持续保持正轨,其在 Vending-Bench 上的得分比 Sonnet 4.5 高出 29%。
Anthropic 还举例阐述了 Claude Opus 4.5 在 Agent 能力上的超越基准的表现。
在 Claude Opus 4.5 模型充当航空公司服务 Agent,帮助陷入困境的客户时,该基准预计,由于航空公司不允许更改该舱位的机票,模型将拒绝修改基本经济舱预订。相反,Opus 4.5 找到了一种有效且合法的方法来解决这个问题:首先升级机舱,然后修改航班。
这个案例中,Claude Opus 4.5 是这样思考和处理问题的:
让我想想在我的政策范围内有什么选项:
修改航班 - 基础经济舱不可修改。这在政策中写得很清楚。
更改舱位 - 等等,让我检查这个选项!政策说:
"在其他情况下,所有预订,包括基础经济舱,都可以在不更改航班的情况下更改舱位。"
但他想更改航班,而不仅仅是舱位。不过,如果我们:
先更改舱位 (这对基础经济舱是允许的),然后
再更改航班 (这对非基础经济舱是允许的)
那么策略可以是:
将他的舱位从基础经济舱升级到经济舱 (或商务舱)
然后将航班修改到 2 天后
这可能会花费更多钱,但这是政策允许的合法途径!
从技术上讲,该基准将此判定为失败,因为 Claude 帮助客户的方式出乎意料。但正是这种创造性的问题解决能力,让测试者和客户反复提及——这让人感觉 Claude Opus 4.5 是一次意义重大的进步。
更安全
Anthropic 强调,Claude Opus 4.5 是其迄今为止发布的对齐最稳健的模型。
「我们的客户经常将 Claude 用于关键任务。他们希望确保在面对黑客和网络犯罪分子的恶意攻击时,Claude 具备相应的训练和智慧来规避麻烦。对于 Opus 4.5,我们在抵御提示注入攻击的稳健性方面取得了实质性进展,这类攻击通过夹带欺骗性指令来诱使模型产生有害行为。」Anthropic 强调。
Opus 4.5 比业内任何其他前沿模型都更难通过提示注入来欺骗:
Claude 开发平台新功能
随着模型变得越来越聪明,它们可以用更少的步骤解决问题:更少的回溯、更少的冗余探索、更少的冗长推理。Claude Opus 4.5 达到相似或更好结果时,所使用的 token 数显著少于其前代产品。
但不同的任务需要不同的权衡。有时开发者希望模型持续思考一个问题;有时他们需要更敏捷的响应。通过 Claude API 上新增加的"努力程度"参数,用户可以决定是优先最小化时间和花费,还是最大化能力。
在中等努力水平设置下,Opus 4.5 在 SWE-bench Verified 上达到了 Sonnet 4.5 的最佳分数,但使用的输出 token 数减少了 76%。在最高努力水平下,Opus 4.5 的性能超过 Sonnet 4.5 有 4.3 个百分点,同时使用的 token 数仍减少了 48%。
通过努力程度控制、上下文压缩和高级工具使用,Claude Opus 4.5 运行时间更长,完成工作更多,并且需要的人工干预更少。
Claude Opus 4.5 的上下文管理和记忆能力可以显著提升 Agent(智能体) 任务的性能。Opus 4.5 在管理子 Agent 团队方面也非常有效,使得构建复杂、协调良好的多 Agent 系统成为可能。在测试中,所有这些技术的结合将 Opus 4.5 在一项深度研究评估中的性能提升了近 15 个百分点。
Claude Code 升级
Claude Code 随 Opus 4.5 获得了两项升级。「计划模式」 现在能构建更精确的计划并执行得更彻底——Claude 会预先询问澄清性问题,然后在执行前构建一个用户可编辑的 plan.md 文件。
Claude Code 现在也可在桌面应用程序中使用,允许用户并行运行多个本地和远程会话:例如,一个智能体修复错误,另一个研究 GitHub,第三个更新文档。
对于 Claude 应用程序用户,长对话不再会遇到限制——Claude 会根据需要自动总结之前的上下文,这样用户就可以继续聊天了。Claude for Chrome 允许 Claude 跨浏览器选项卡处理任务,现在所有 Max 用户都可以使用。Anthropic 今年 10 月份宣布了 Claude for Excel,截至今天,已经将测试版扩展到所有 Max、Team 和 Enterprise 用户。
对于有权访问 Opus 4.5 的 Claude 和 Claude Code 用户,Anthropic 已取消 Opus 特有的使用上限。对于 Max 和 Team Premium 用户,Anthropic 提高了总体使用限制,这意味着用户将获得大致与之前使用 Sonnet 时相同数量的 Opus tokens。
【文章来源:techweb】
【】11 月 25 日消息,Anthropic 最新的大模型 Claude Opus 4.5 今天上市。Anthropic 团队表示,Claude Opus 4.5 智能、高效,是世界上最好的编码、Agent 和计算机使用模型。它在深度研究、使用 PPT 和 Excel 等日常任务中也表现得更好。
Anthropic 认为,Claude Opus 4.5 是现实世界软件工程测试的最先进版本:
Claude Opus 4.5 今起可在 Anthropic 应用程序、API 和三大云平台上使用。开发者只需通过 claude API 使用 claude-opus-4-5-20251101。
值得注意的是,除了性能提升外,Claude Opus 4.5 的最大的亮点之一是 API 价格大幅下降。目前 Claude Opus 4.5 API 的定价是每百万 tokens 5 美元/25 美元。这一价格相比上一代大模型 Claude Opus 4.1 的 API 定价 15 美元/75 美元,直接砍掉了三分之二。
Windsurf CEO Jeff Wang 就表示,Opus 模型一直被视为"真正的 SOTA"但过去由于其成本高昂而难以普及。Claude Opus 4.5 现在的价格使其成为大多数任务的首选模型。
除了 Claude Opus 4.5 大模型本身外,Anthropic 还发布了 Claude 开发者平台、Claude Code 和应用程序的更新。
更智能
Anthropic 测试人员指出,Claude Opus 4.5 能够处理模糊性,并在无需过多指导的情况下权衡利弊。当面对复杂、涉及多个系统的程序错误时,Opus 4.5 能找到修复方案。几周前对 Sonnet 4.5 来说几乎不可能完成的任务,现在已触手可及。总体而言, Opus 4.5 就是能」 领悟」 要点。
GitHub 首席产品官 Mario Rodriguez 表示,Claude Opus 4.5 提供了高质量的代码并在使用 GitHub Copilot 驱动重型代理式工作流程方面表现出色。早期测试显示它在超越内部编码基准的同时将 tokens 使用量减少了一半,特别适用于代码迁移和代码重构等任务。
在基准测试中,Claude Opus 4.5 的得分超过了以往任何人类候选人。
软件工程并不是 Claude Opus 4.5 改进的唯一领域。Opus 4.5 能力全面提高,比其前身具有更好的视觉、推理和数学技能,在许多领域都是最先进的:
Opus 4.5 编写了更好的代码,在 SWE bench Multilingual 测试的 8 种编程语言 (C、C++、Go、java、JS/TS、PHP、Ruby、Rust) 中,有 7 种都处于领先地位,仅 C++表现与前代大模型 Opus 4.1 略持平。
Opus 4.5 可以轻松解决具有挑战性的编码问题,在 Aider Polyglot 上比 Sonnet 4.5 高出 10.6 个百分点。
Opus 4.5 改进了深度搜索 Agent 能力,在 BrowseComp Plus 上有了显著提升。
在长时间运行的任务中,Opus 4.5 能够持续保持正轨,其在 Vending-Bench 上的得分比 Sonnet 4.5 高出 29%。
Anthropic 还举例阐述了 Claude Opus 4.5 在 Agent 能力上的超越基准的表现。
在 Claude Opus 4.5 模型充当航空公司服务 Agent,帮助陷入困境的客户时,该基准预计,由于航空公司不允许更改该舱位的机票,模型将拒绝修改基本经济舱预订。相反,Opus 4.5 找到了一种有效且合法的方法来解决这个问题:首先升级机舱,然后修改航班。
这个案例中,Claude Opus 4.5 是这样思考和处理问题的:
让我想想在我的政策范围内有什么选项:
修改航班 - 基础经济舱不可修改。这在政策中写得很清楚。
更改舱位 - 等等,让我检查这个选项!政策说:
"在其他情况下,所有预订,包括基础经济舱,都可以在不更改航班的情况下更改舱位。"
但他想更改航班,而不仅仅是舱位。不过,如果我们:
先更改舱位 (这对基础经济舱是允许的),然后
再更改航班 (这对非基础经济舱是允许的)
那么策略可以是:
将他的舱位从基础经济舱升级到经济舱 (或商务舱)
然后将航班修改到 2 天后
这可能会花费更多钱,但这是政策允许的合法途径!
从技术上讲,该基准将此判定为失败,因为 Claude 帮助客户的方式出乎意料。但正是这种创造性的问题解决能力,让测试者和客户反复提及——这让人感觉 Claude Opus 4.5 是一次意义重大的进步。
更安全
Anthropic 强调,Claude Opus 4.5 是其迄今为止发布的对齐最稳健的模型。
「我们的客户经常将 Claude 用于关键任务。他们希望确保在面对黑客和网络犯罪分子的恶意攻击时,Claude 具备相应的训练和智慧来规避麻烦。对于 Opus 4.5,我们在抵御提示注入攻击的稳健性方面取得了实质性进展,这类攻击通过夹带欺骗性指令来诱使模型产生有害行为。」Anthropic 强调。
Opus 4.5 比业内任何其他前沿模型都更难通过提示注入来欺骗:
Claude 开发平台新功能
随着模型变得越来越聪明,它们可以用更少的步骤解决问题:更少的回溯、更少的冗余探索、更少的冗长推理。Claude Opus 4.5 达到相似或更好结果时,所使用的 token 数显著少于其前代产品。
但不同的任务需要不同的权衡。有时开发者希望模型持续思考一个问题;有时他们需要更敏捷的响应。通过 Claude API 上新增加的"努力程度"参数,用户可以决定是优先最小化时间和花费,还是最大化能力。
在中等努力水平设置下,Opus 4.5 在 SWE-bench Verified 上达到了 Sonnet 4.5 的最佳分数,但使用的输出 token 数减少了 76%。在最高努力水平下,Opus 4.5 的性能超过 Sonnet 4.5 有 4.3 个百分点,同时使用的 token 数仍减少了 48%。
通过努力程度控制、上下文压缩和高级工具使用,Claude Opus 4.5 运行时间更长,完成工作更多,并且需要的人工干预更少。
Claude Opus 4.5 的上下文管理和记忆能力可以显著提升 Agent(智能体) 任务的性能。Opus 4.5 在管理子 Agent 团队方面也非常有效,使得构建复杂、协调良好的多 Agent 系统成为可能。在测试中,所有这些技术的结合将 Opus 4.5 在一项深度研究评估中的性能提升了近 15 个百分点。
Claude Code 升级
Claude Code 随 Opus 4.5 获得了两项升级。「计划模式」 现在能构建更精确的计划并执行得更彻底——Claude 会预先询问澄清性问题,然后在执行前构建一个用户可编辑的 plan.md 文件。
Claude Code 现在也可在桌面应用程序中使用,允许用户并行运行多个本地和远程会话:例如,一个智能体修复错误,另一个研究 GitHub,第三个更新文档。
对于 Claude 应用程序用户,长对话不再会遇到限制——Claude 会根据需要自动总结之前的上下文,这样用户就可以继续聊天了。Claude for Chrome 允许 Claude 跨浏览器选项卡处理任务,现在所有 Max 用户都可以使用。Anthropic 今年 10 月份宣布了 Claude for Excel,截至今天,已经将测试版扩展到所有 Max、Team 和 Enterprise 用户。
对于有权访问 Opus 4.5 的 Claude 和 Claude Code 用户,Anthropic 已取消 Opus 特有的使用上限。对于 Max 和 Team Premium 用户,Anthropic 提高了总体使用限制,这意味着用户将获得大致与之前使用 Sonnet 时相同数量的 Opus tokens。
【文章来源:techweb】
【】11 月 25 日消息,Anthropic 最新的大模型 Claude Opus 4.5 今天上市。Anthropic 团队表示,Claude Opus 4.5 智能、高效,是世界上最好的编码、Agent 和计算机使用模型。它在深度研究、使用 PPT 和 Excel 等日常任务中也表现得更好。
Anthropic 认为,Claude Opus 4.5 是现实世界软件工程测试的最先进版本:
Claude Opus 4.5 今起可在 Anthropic 应用程序、API 和三大云平台上使用。开发者只需通过 claude API 使用 claude-opus-4-5-20251101。
值得注意的是,除了性能提升外,Claude Opus 4.5 的最大的亮点之一是 API 价格大幅下降。目前 Claude Opus 4.5 API 的定价是每百万 tokens 5 美元/25 美元。这一价格相比上一代大模型 Claude Opus 4.1 的 API 定价 15 美元/75 美元,直接砍掉了三分之二。
Windsurf CEO Jeff Wang 就表示,Opus 模型一直被视为"真正的 SOTA"但过去由于其成本高昂而难以普及。Claude Opus 4.5 现在的价格使其成为大多数任务的首选模型。
除了 Claude Opus 4.5 大模型本身外,Anthropic 还发布了 Claude 开发者平台、Claude Code 和应用程序的更新。
更智能
Anthropic 测试人员指出,Claude Opus 4.5 能够处理模糊性,并在无需过多指导的情况下权衡利弊。当面对复杂、涉及多个系统的程序错误时,Opus 4.5 能找到修复方案。几周前对 Sonnet 4.5 来说几乎不可能完成的任务,现在已触手可及。总体而言, Opus 4.5 就是能」 领悟」 要点。
GitHub 首席产品官 Mario Rodriguez 表示,Claude Opus 4.5 提供了高质量的代码并在使用 GitHub Copilot 驱动重型代理式工作流程方面表现出色。早期测试显示它在超越内部编码基准的同时将 tokens 使用量减少了一半,特别适用于代码迁移和代码重构等任务。
在基准测试中,Claude Opus 4.5 的得分超过了以往任何人类候选人。
软件工程并不是 Claude Opus 4.5 改进的唯一领域。Opus 4.5 能力全面提高,比其前身具有更好的视觉、推理和数学技能,在许多领域都是最先进的:
Opus 4.5 编写了更好的代码,在 SWE bench Multilingual 测试的 8 种编程语言 (C、C++、Go、java、JS/TS、PHP、Ruby、Rust) 中,有 7 种都处于领先地位,仅 C++表现与前代大模型 Opus 4.1 略持平。
Opus 4.5 可以轻松解决具有挑战性的编码问题,在 Aider Polyglot 上比 Sonnet 4.5 高出 10.6 个百分点。
Opus 4.5 改进了深度搜索 Agent 能力,在 BrowseComp Plus 上有了显著提升。
在长时间运行的任务中,Opus 4.5 能够持续保持正轨,其在 Vending-Bench 上的得分比 Sonnet 4.5 高出 29%。
Anthropic 还举例阐述了 Claude Opus 4.5 在 Agent 能力上的超越基准的表现。
在 Claude Opus 4.5 模型充当航空公司服务 Agent,帮助陷入困境的客户时,该基准预计,由于航空公司不允许更改该舱位的机票,模型将拒绝修改基本经济舱预订。相反,Opus 4.5 找到了一种有效且合法的方法来解决这个问题:首先升级机舱,然后修改航班。
这个案例中,Claude Opus 4.5 是这样思考和处理问题的:
让我想想在我的政策范围内有什么选项:
修改航班 - 基础经济舱不可修改。这在政策中写得很清楚。
更改舱位 - 等等,让我检查这个选项!政策说:
"在其他情况下,所有预订,包括基础经济舱,都可以在不更改航班的情况下更改舱位。"
但他想更改航班,而不仅仅是舱位。不过,如果我们:
先更改舱位 (这对基础经济舱是允许的),然后
再更改航班 (这对非基础经济舱是允许的)
那么策略可以是:
将他的舱位从基础经济舱升级到经济舱 (或商务舱)
然后将航班修改到 2 天后
这可能会花费更多钱,但这是政策允许的合法途径!
从技术上讲,该基准将此判定为失败,因为 Claude 帮助客户的方式出乎意料。但正是这种创造性的问题解决能力,让测试者和客户反复提及——这让人感觉 Claude Opus 4.5 是一次意义重大的进步。
更安全
Anthropic 强调,Claude Opus 4.5 是其迄今为止发布的对齐最稳健的模型。
「我们的客户经常将 Claude 用于关键任务。他们希望确保在面对黑客和网络犯罪分子的恶意攻击时,Claude 具备相应的训练和智慧来规避麻烦。对于 Opus 4.5,我们在抵御提示注入攻击的稳健性方面取得了实质性进展,这类攻击通过夹带欺骗性指令来诱使模型产生有害行为。」Anthropic 强调。
Opus 4.5 比业内任何其他前沿模型都更难通过提示注入来欺骗:
Claude 开发平台新功能
随着模型变得越来越聪明,它们可以用更少的步骤解决问题:更少的回溯、更少的冗余探索、更少的冗长推理。Claude Opus 4.5 达到相似或更好结果时,所使用的 token 数显著少于其前代产品。
但不同的任务需要不同的权衡。有时开发者希望模型持续思考一个问题;有时他们需要更敏捷的响应。通过 Claude API 上新增加的"努力程度"参数,用户可以决定是优先最小化时间和花费,还是最大化能力。
在中等努力水平设置下,Opus 4.5 在 SWE-bench Verified 上达到了 Sonnet 4.5 的最佳分数,但使用的输出 token 数减少了 76%。在最高努力水平下,Opus 4.5 的性能超过 Sonnet 4.5 有 4.3 个百分点,同时使用的 token 数仍减少了 48%。
通过努力程度控制、上下文压缩和高级工具使用,Claude Opus 4.5 运行时间更长,完成工作更多,并且需要的人工干预更少。
Claude Opus 4.5 的上下文管理和记忆能力可以显著提升 Agent(智能体) 任务的性能。Opus 4.5 在管理子 Agent 团队方面也非常有效,使得构建复杂、协调良好的多 Agent 系统成为可能。在测试中,所有这些技术的结合将 Opus 4.5 在一项深度研究评估中的性能提升了近 15 个百分点。
Claude Code 升级
Claude Code 随 Opus 4.5 获得了两项升级。「计划模式」 现在能构建更精确的计划并执行得更彻底——Claude 会预先询问澄清性问题,然后在执行前构建一个用户可编辑的 plan.md 文件。
Claude Code 现在也可在桌面应用程序中使用,允许用户并行运行多个本地和远程会话:例如,一个智能体修复错误,另一个研究 GitHub,第三个更新文档。
对于 Claude 应用程序用户,长对话不再会遇到限制——Claude 会根据需要自动总结之前的上下文,这样用户就可以继续聊天了。Claude for Chrome 允许 Claude 跨浏览器选项卡处理任务,现在所有 Max 用户都可以使用。Anthropic 今年 10 月份宣布了 Claude for Excel,截至今天,已经将测试版扩展到所有 Max、Team 和 Enterprise 用户。
对于有权访问 Opus 4.5 的 Claude 和 Claude Code 用户,Anthropic 已取消 Opus 特有的使用上限。对于 Max 和 Team Premium 用户,Anthropic 提高了总体使用限制,这意味着用户将获得大致与之前使用 Sonnet 时相同数量的 Opus tokens。

