


【文章来源:techweb】
【TechWeb】1 月 22 日消息,百川智能正式发布 Baichuan-M3 Plus,严肃医疗场景下的问答准确性、可靠性,再次刷新了刚刚推出的 M3 所创下的世界纪录。凭借独创的六源循证技术与 M3 基座结合,M3 Plus 将幻觉率降低至 2.6%,低于 Open Evidence,达到全球最低水平;首创 「证据锚定」 技术,不仅给出引文来源,还能将模型生成的每一句医学结论,精确锚定到原始论文中的对应证据段落,使 AI 的医学判断真正做到可核验、可追责、可教学。
同时,百川宣布推出 「海纳百川」 计划,将全球最低幻觉的循证增强医疗大模型以 API 形式,免费开放给中国医疗服务机构,共同繁荣国内的 AI 医疗生态,推动中国 AI 医疗的变革,让每一位中国医务工作者都能拥有可靠、好用的 AI 助手。
上周百川 M3 大模型的正式开源,M3 不仅在 Healthbench、Healthbench Hard 等多个权威评测中登顶榜首,实现了对 GPT-5.2 的全面超越,更在 OpenAI 引以为傲的低幻觉领域完成超越,以 3.5% 的幻觉率领跑全球。M3 Plus 的事实性幻觉降低到新的 SOTA,仅 2.6%,相较 GPT-5.2 大幅下降超 30%。即便与行业标杆 Open Evidence 相比,M3 Plus 也完成了超越。
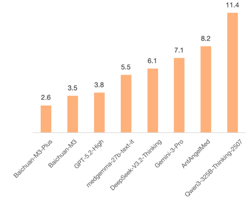
值得注意的是,百川 M3 Plus 首创 「证据锚定 (Evidence Anchoring)」 技术,不是简单标注 「引用自哪篇文献」,而是要求模型生成的每一句医学结论,都必须精确对应到原始论文或指南中的具体证据段落。每一句判断,都能被逐字溯源、逐条核验。
为实现这一目标,百川将 「证据锚定」 作为独立训练目标,引入 Citation Reward Model,对错误引用进行明确惩罚,让模型只能在 「确实有证据支持」 的空间中推理与生成。最终,结论与证据段落的匹配准确率超过 95%,真正让 AI 的医学判断做到可核验、可追责、可教学。
M3 Plus 在系统层面进行了全面的工程重构,通过 MoE 架构优化、模型量化以及 Gated Eagle-3 投机解码等关键技术,在严格保证模型能力与可靠性的前提下,实现了 API 调用成本较上一代降低 70%,为 AI 在医疗场景的规模化应用扫清了关键障碍。百川全面开放 M3 Plus 的技术能力,API 限时免费体验 15 天,所有开发者均可申请使用。
另外,百川发起 「海纳百川」 计划:面向所有服务医务工作者的机构,免费提供全球幻觉最低循证增强医疗大模型 M3 Plus 的 API,把服务医生的 AI 能力直接交到生态伙伴手里。
附 「海纳百川」 计划|参与条件:
适用对象:
为医务工作者提供服务的机构
医务工作者包括医生、药剂师、医技师、护士、健管师、医学生等
适用场景仅限于:
临床辅助决策、医学教育
用途限制:
仅用于真实服务场景、不得用于数据生产
使用要求:
产品需明确展示 Powered by 百川、不得对模型输出进行影响准确性的修改
【文章来源:techweb】
【TechWeb】1 月 22 日消息,百川智能正式发布 Baichuan-M3 Plus,严肃医疗场景下的问答准确性、可靠性,再次刷新了刚刚推出的 M3 所创下的世界纪录。凭借独创的六源循证技术与 M3 基座结合,M3 Plus 将幻觉率降低至 2.6%,低于 Open Evidence,达到全球最低水平;首创 「证据锚定」 技术,不仅给出引文来源,还能将模型生成的每一句医学结论,精确锚定到原始论文中的对应证据段落,使 AI 的医学判断真正做到可核验、可追责、可教学。
同时,百川宣布推出 「海纳百川」 计划,将全球最低幻觉的循证增强医疗大模型以 API 形式,免费开放给中国医疗服务机构,共同繁荣国内的 AI 医疗生态,推动中国 AI 医疗的变革,让每一位中国医务工作者都能拥有可靠、好用的 AI 助手。
上周百川 M3 大模型的正式开源,M3 不仅在 Healthbench、Healthbench Hard 等多个权威评测中登顶榜首,实现了对 GPT-5.2 的全面超越,更在 OpenAI 引以为傲的低幻觉领域完成超越,以 3.5% 的幻觉率领跑全球。M3 Plus 的事实性幻觉降低到新的 SOTA,仅 2.6%,相较 GPT-5.2 大幅下降超 30%。即便与行业标杆 Open Evidence 相比,M3 Plus 也完成了超越。
值得注意的是,百川 M3 Plus 首创 「证据锚定 (Evidence Anchoring)」 技术,不是简单标注 「引用自哪篇文献」,而是要求模型生成的每一句医学结论,都必须精确对应到原始论文或指南中的具体证据段落。每一句判断,都能被逐字溯源、逐条核验。
为实现这一目标,百川将 「证据锚定」 作为独立训练目标,引入 Citation Reward Model,对错误引用进行明确惩罚,让模型只能在 「确实有证据支持」 的空间中推理与生成。最终,结论与证据段落的匹配准确率超过 95%,真正让 AI 的医学判断做到可核验、可追责、可教学。
M3 Plus 在系统层面进行了全面的工程重构,通过 MoE 架构优化、模型量化以及 Gated Eagle-3 投机解码等关键技术,在严格保证模型能力与可靠性的前提下,实现了 API 调用成本较上一代降低 70%,为 AI 在医疗场景的规模化应用扫清了关键障碍。百川全面开放 M3 Plus 的技术能力,API 限时免费体验 15 天,所有开发者均可申请使用。
另外,百川发起 「海纳百川」 计划:面向所有服务医务工作者的机构,免费提供全球幻觉最低循证增强医疗大模型 M3 Plus 的 API,把服务医生的 AI 能力直接交到生态伙伴手里。
附 「海纳百川」 计划|参与条件:
适用对象:
为医务工作者提供服务的机构
医务工作者包括医生、药剂师、医技师、护士、健管师、医学生等
适用场景仅限于:
临床辅助决策、医学教育
用途限制:
仅用于真实服务场景、不得用于数据生产
使用要求:
产品需明确展示 Powered by 百川、不得对模型输出进行影响准确性的修改
【文章来源:techweb】
【TechWeb】1 月 22 日消息,百川智能正式发布 Baichuan-M3 Plus,严肃医疗场景下的问答准确性、可靠性,再次刷新了刚刚推出的 M3 所创下的世界纪录。凭借独创的六源循证技术与 M3 基座结合,M3 Plus 将幻觉率降低至 2.6%,低于 Open Evidence,达到全球最低水平;首创 「证据锚定」 技术,不仅给出引文来源,还能将模型生成的每一句医学结论,精确锚定到原始论文中的对应证据段落,使 AI 的医学判断真正做到可核验、可追责、可教学。
同时,百川宣布推出 「海纳百川」 计划,将全球最低幻觉的循证增强医疗大模型以 API 形式,免费开放给中国医疗服务机构,共同繁荣国内的 AI 医疗生态,推动中国 AI 医疗的变革,让每一位中国医务工作者都能拥有可靠、好用的 AI 助手。
上周百川 M3 大模型的正式开源,M3 不仅在 Healthbench、Healthbench Hard 等多个权威评测中登顶榜首,实现了对 GPT-5.2 的全面超越,更在 OpenAI 引以为傲的低幻觉领域完成超越,以 3.5% 的幻觉率领跑全球。M3 Plus 的事实性幻觉降低到新的 SOTA,仅 2.6%,相较 GPT-5.2 大幅下降超 30%。即便与行业标杆 Open Evidence 相比,M3 Plus 也完成了超越。
值得注意的是,百川 M3 Plus 首创 「证据锚定 (Evidence Anchoring)」 技术,不是简单标注 「引用自哪篇文献」,而是要求模型生成的每一句医学结论,都必须精确对应到原始论文或指南中的具体证据段落。每一句判断,都能被逐字溯源、逐条核验。
为实现这一目标,百川将 「证据锚定」 作为独立训练目标,引入 Citation Reward Model,对错误引用进行明确惩罚,让模型只能在 「确实有证据支持」 的空间中推理与生成。最终,结论与证据段落的匹配准确率超过 95%,真正让 AI 的医学判断做到可核验、可追责、可教学。
M3 Plus 在系统层面进行了全面的工程重构,通过 MoE 架构优化、模型量化以及 Gated Eagle-3 投机解码等关键技术,在严格保证模型能力与可靠性的前提下,实现了 API 调用成本较上一代降低 70%,为 AI 在医疗场景的规模化应用扫清了关键障碍。百川全面开放 M3 Plus 的技术能力,API 限时免费体验 15 天,所有开发者均可申请使用。
另外,百川发起 「海纳百川」 计划:面向所有服务医务工作者的机构,免费提供全球幻觉最低循证增强医疗大模型 M3 Plus 的 API,把服务医生的 AI 能力直接交到生态伙伴手里。
附 「海纳百川」 计划|参与条件:
适用对象:
为医务工作者提供服务的机构
医务工作者包括医生、药剂师、医技师、护士、健管师、医学生等
适用场景仅限于:
临床辅助决策、医学教育
用途限制:
仅用于真实服务场景、不得用于数据生产
使用要求:
产品需明确展示 Powered by 百川、不得对模型输出进行影响准确性的修改
【文章来源:techweb】
【TechWeb】1 月 22 日消息,百川智能正式发布 Baichuan-M3 Plus,严肃医疗场景下的问答准确性、可靠性,再次刷新了刚刚推出的 M3 所创下的世界纪录。凭借独创的六源循证技术与 M3 基座结合,M3 Plus 将幻觉率降低至 2.6%,低于 Open Evidence,达到全球最低水平;首创 「证据锚定」 技术,不仅给出引文来源,还能将模型生成的每一句医学结论,精确锚定到原始论文中的对应证据段落,使 AI 的医学判断真正做到可核验、可追责、可教学。
同时,百川宣布推出 「海纳百川」 计划,将全球最低幻觉的循证增强医疗大模型以 API 形式,免费开放给中国医疗服务机构,共同繁荣国内的 AI 医疗生态,推动中国 AI 医疗的变革,让每一位中国医务工作者都能拥有可靠、好用的 AI 助手。
上周百川 M3 大模型的正式开源,M3 不仅在 Healthbench、Healthbench Hard 等多个权威评测中登顶榜首,实现了对 GPT-5.2 的全面超越,更在 OpenAI 引以为傲的低幻觉领域完成超越,以 3.5% 的幻觉率领跑全球。M3 Plus 的事实性幻觉降低到新的 SOTA,仅 2.6%,相较 GPT-5.2 大幅下降超 30%。即便与行业标杆 Open Evidence 相比,M3 Plus 也完成了超越。
值得注意的是,百川 M3 Plus 首创 「证据锚定 (Evidence Anchoring)」 技术,不是简单标注 「引用自哪篇文献」,而是要求模型生成的每一句医学结论,都必须精确对应到原始论文或指南中的具体证据段落。每一句判断,都能被逐字溯源、逐条核验。
为实现这一目标,百川将 「证据锚定」 作为独立训练目标,引入 Citation Reward Model,对错误引用进行明确惩罚,让模型只能在 「确实有证据支持」 的空间中推理与生成。最终,结论与证据段落的匹配准确率超过 95%,真正让 AI 的医学判断做到可核验、可追责、可教学。
M3 Plus 在系统层面进行了全面的工程重构,通过 MoE 架构优化、模型量化以及 Gated Eagle-3 投机解码等关键技术,在严格保证模型能力与可靠性的前提下,实现了 API 调用成本较上一代降低 70%,为 AI 在医疗场景的规模化应用扫清了关键障碍。百川全面开放 M3 Plus 的技术能力,API 限时免费体验 15 天,所有开发者均可申请使用。
另外,百川发起 「海纳百川」 计划:面向所有服务医务工作者的机构,免费提供全球幻觉最低循证增强医疗大模型 M3 Plus 的 API,把服务医生的 AI 能力直接交到生态伙伴手里。
附 「海纳百川」 计划|参与条件:
适用对象:
为医务工作者提供服务的机构
医务工作者包括医生、药剂师、医技师、护士、健管师、医学生等
适用场景仅限于:
临床辅助决策、医学教育
用途限制:
仅用于真实服务场景、不得用于数据生产
使用要求:
产品需明确展示 Powered by 百川、不得对模型输出进行影响准确性的修改

