

【文章来源:techweb】
【TechWeb】2 月 12 日消息,近日,阿里巴巴集团旗下高德正式发布具身操作基座模型 ABot-M0 与具身导航基座模型 ABot-N0,补齐了具身机器人规模化落地的两块核心能力——操作的通用性和导航的长程性,并刷新了全球多项权威评测纪录。
ABot-M0
长期以来,机器人技术的规模化应用面临诸多挑战,其中关键之一在于数据的割裂、动作表示的不统一以及空间理解能力的不足。不同厂商、不同形态的机器人往往使用各自独立的数据体系,导致模型难以跨平台复用,训练效率受限,部署成本高。
高德推出的 ABot-M0 作为一款通用的具身操作基础模型,从 「数据统一—算法革新—空间感知」 三个方面进行了系统性重构,致力于提升模型在多样化机器人形态和任务场景下的泛化能力。
ABot-M0 基于全球开源资源,整合超过 600 万条真实操作轨迹,构建了目前规模最大的通用机器人数据集。通过统一动作表示、坐标系与控制频率,并采用增量式动作建模,实现了跨平台数据融合,支撑了完全基于公开数据的预训练。
算法革新上,ABot-M0 提出了全球首个动作流形学习:有效的机器人动作受限于物理规律、任务目标与环境约束,集中分布在低维结构化的流形上。设计了 AML(Action Manifold Learning) 算法,使模型能够直接预测结构合理、物理可行的动作序列,提升策略的稳定性与解码效率。
为增强空间感知,ABot-M0 引入 3D 感知模块,增强模型对 「前后、远近、遮挡」 等空间语义的理解,在复杂环境中实现更精准的操作决策。
在 Libero、Libero-Plus、RoboCasa 基准测试中,该模型在包含复杂任务组合与动态场景扰动的设定下,平均任务成功率均达到 SOTA。其中,Libero-Plus 基准上达到了 80.5%,较业界先进方案 pi0 提升近 30%,展现了其在高扰动高难度具身操作任务中的领先性能。
ABot-N0
导航是机器人进入物理开放世界的核心基础能力,机器人需要在动态且存在干扰的环境里展现出通用的行动能力,如跨场景送物或跟随服务,这同时也是具身智能演进的终极命题。
然而,当前的具身导航研究普遍深陷 「碎片化」:主流方法往往针对特定任务构建孤立的专用架构,这不仅限制了模型的跨任务泛化能力,更阻碍了智能体从海量异构数据中提取统一物理先验的可能性。
这也是当前机器人常陷于 「环境看不懂、动作做不准」 的核心原因,复杂指令 (如 「去门口帮我看看快递」) 更是难以执行。
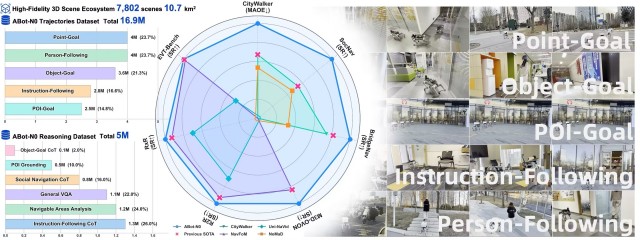
高德推出的具身导航基座模型 ABot-N0,以 「全任务一统」 为核心目标,并实现全球首次在单一模型中完整集成 Point-Goal(点位导航)、Object-Goal(目标导航)、Instruction-Following(指令跟随)、POI-Goal(兴趣点导航) 与 Person-Following(人物跟随) 五大导航任务,有效突破了传统架构中任务割裂的瓶颈。
比如,当用户对搭载 ABot-N0 的具身机器人说:「带我去奶茶店买一杯奶茶,再帮我占个座。」 时系统会自动分解为具体的导航任务:首先执行 Point-Goal,根据地图记忆接近奶茶店区域;之后切换至 POI-Goal,精准锁定店铺入口并靠近;随后触发 Instruction-Following,进入店铺并导航至柜台;最后执行 Object-Goal,在店内寻找空沙发并停靠。
相较于只能支持部分任务的具身导航模型,高德 ABot-N0 所实现的五大导航任务给长程复杂任务的执行提供了可行的解决方案。这一能力背后,是高德在架构设计、数据引擎和系统框架上的关键革新。
在模型架构上,ABot-N0 采用层次化的 「大脑‑动作」 设计哲学:由 「认知大脑」 理解指令并做推理,由基于流匹配 (Flow Matching) 的 「动作专家」 生成精确且多峰分布的连续轨迹 。训练上,先让模型做认知训练热身,再用部分认知数据和海量导航动作进行联合监督微调,最后用强化学习把导航决策对齐到人类偏好的行为价值,最终打造出真实环境中更通用的 VLA 基座模型。
在数据侧,依托高德长期沉淀的场景资产和专家示例,高德构建了业内最大规模的具身导航数据引擎,涵盖约 8000 个高保真 3D 场景等海量时空数据与近 1700 万条专家示例,从而增强模型在真实环境中的泛化能力与鲁棒性。
基于 ABot-N0 的系统性创新,其在 CityWalker、SocNav、R2R-CE/RxR-CE、HM3D-OVON、BridgeNav、EVT-Bench 七大权威基准测试中全面刷新了世界纪录。其中在 SocNav 闭环仿真中,成功率 (SR) 飙升 40.5%,在 HM3D-OVON 评测中成功率 (SR) 提升 8.8%,均显著强于之前的 SOTA 模型。
此外,为了解决机器人在执行长程复杂任务时的任务拆解与容错问题,高德提出了可落地的 Agentic Navigation System 具身导航系统框架,行成从 「读懂指令」 到 「长程复杂任务执行」 的闭环能力架构,支持机器人在执行过程中持续感知、记忆、决策与纠错。系统已成功部署于真实四足机器人平台,并在边缘侧实现了高效推理与闭环控制,验证了其在动态现实环境中的泛化性能与工业级稳定性。
【文章来源:techweb】
【TechWeb】2 月 12 日消息,近日,阿里巴巴集团旗下高德正式发布具身操作基座模型 ABot-M0 与具身导航基座模型 ABot-N0,补齐了具身机器人规模化落地的两块核心能力——操作的通用性和导航的长程性,并刷新了全球多项权威评测纪录。
ABot-M0
长期以来,机器人技术的规模化应用面临诸多挑战,其中关键之一在于数据的割裂、动作表示的不统一以及空间理解能力的不足。不同厂商、不同形态的机器人往往使用各自独立的数据体系,导致模型难以跨平台复用,训练效率受限,部署成本高。
高德推出的 ABot-M0 作为一款通用的具身操作基础模型,从 「数据统一—算法革新—空间感知」 三个方面进行了系统性重构,致力于提升模型在多样化机器人形态和任务场景下的泛化能力。
ABot-M0 基于全球开源资源,整合超过 600 万条真实操作轨迹,构建了目前规模最大的通用机器人数据集。通过统一动作表示、坐标系与控制频率,并采用增量式动作建模,实现了跨平台数据融合,支撑了完全基于公开数据的预训练。
算法革新上,ABot-M0 提出了全球首个动作流形学习:有效的机器人动作受限于物理规律、任务目标与环境约束,集中分布在低维结构化的流形上。设计了 AML(Action Manifold Learning) 算法,使模型能够直接预测结构合理、物理可行的动作序列,提升策略的稳定性与解码效率。
为增强空间感知,ABot-M0 引入 3D 感知模块,增强模型对 「前后、远近、遮挡」 等空间语义的理解,在复杂环境中实现更精准的操作决策。
在 Libero、Libero-Plus、RoboCasa 基准测试中,该模型在包含复杂任务组合与动态场景扰动的设定下,平均任务成功率均达到 SOTA。其中,Libero-Plus 基准上达到了 80.5%,较业界先进方案 pi0 提升近 30%,展现了其在高扰动高难度具身操作任务中的领先性能。
ABot-N0
导航是机器人进入物理开放世界的核心基础能力,机器人需要在动态且存在干扰的环境里展现出通用的行动能力,如跨场景送物或跟随服务,这同时也是具身智能演进的终极命题。
然而,当前的具身导航研究普遍深陷 「碎片化」:主流方法往往针对特定任务构建孤立的专用架构,这不仅限制了模型的跨任务泛化能力,更阻碍了智能体从海量异构数据中提取统一物理先验的可能性。
这也是当前机器人常陷于 「环境看不懂、动作做不准」 的核心原因,复杂指令 (如 「去门口帮我看看快递」) 更是难以执行。
高德推出的具身导航基座模型 ABot-N0,以 「全任务一统」 为核心目标,并实现全球首次在单一模型中完整集成 Point-Goal(点位导航)、Object-Goal(目标导航)、Instruction-Following(指令跟随)、POI-Goal(兴趣点导航) 与 Person-Following(人物跟随) 五大导航任务,有效突破了传统架构中任务割裂的瓶颈。
比如,当用户对搭载 ABot-N0 的具身机器人说:「带我去奶茶店买一杯奶茶,再帮我占个座。」 时系统会自动分解为具体的导航任务:首先执行 Point-Goal,根据地图记忆接近奶茶店区域;之后切换至 POI-Goal,精准锁定店铺入口并靠近;随后触发 Instruction-Following,进入店铺并导航至柜台;最后执行 Object-Goal,在店内寻找空沙发并停靠。
相较于只能支持部分任务的具身导航模型,高德 ABot-N0 所实现的五大导航任务给长程复杂任务的执行提供了可行的解决方案。这一能力背后,是高德在架构设计、数据引擎和系统框架上的关键革新。
在模型架构上,ABot-N0 采用层次化的 「大脑‑动作」 设计哲学:由 「认知大脑」 理解指令并做推理,由基于流匹配 (Flow Matching) 的 「动作专家」 生成精确且多峰分布的连续轨迹 。训练上,先让模型做认知训练热身,再用部分认知数据和海量导航动作进行联合监督微调,最后用强化学习把导航决策对齐到人类偏好的行为价值,最终打造出真实环境中更通用的 VLA 基座模型。
在数据侧,依托高德长期沉淀的场景资产和专家示例,高德构建了业内最大规模的具身导航数据引擎,涵盖约 8000 个高保真 3D 场景等海量时空数据与近 1700 万条专家示例,从而增强模型在真实环境中的泛化能力与鲁棒性。
基于 ABot-N0 的系统性创新,其在 CityWalker、SocNav、R2R-CE/RxR-CE、HM3D-OVON、BridgeNav、EVT-Bench 七大权威基准测试中全面刷新了世界纪录。其中在 SocNav 闭环仿真中,成功率 (SR) 飙升 40.5%,在 HM3D-OVON 评测中成功率 (SR) 提升 8.8%,均显著强于之前的 SOTA 模型。
此外,为了解决机器人在执行长程复杂任务时的任务拆解与容错问题,高德提出了可落地的 Agentic Navigation System 具身导航系统框架,行成从 「读懂指令」 到 「长程复杂任务执行」 的闭环能力架构,支持机器人在执行过程中持续感知、记忆、决策与纠错。系统已成功部署于真实四足机器人平台,并在边缘侧实现了高效推理与闭环控制,验证了其在动态现实环境中的泛化性能与工业级稳定性。
【文章来源:techweb】
【TechWeb】2 月 12 日消息,近日,阿里巴巴集团旗下高德正式发布具身操作基座模型 ABot-M0 与具身导航基座模型 ABot-N0,补齐了具身机器人规模化落地的两块核心能力——操作的通用性和导航的长程性,并刷新了全球多项权威评测纪录。
ABot-M0
长期以来,机器人技术的规模化应用面临诸多挑战,其中关键之一在于数据的割裂、动作表示的不统一以及空间理解能力的不足。不同厂商、不同形态的机器人往往使用各自独立的数据体系,导致模型难以跨平台复用,训练效率受限,部署成本高。
高德推出的 ABot-M0 作为一款通用的具身操作基础模型,从 「数据统一—算法革新—空间感知」 三个方面进行了系统性重构,致力于提升模型在多样化机器人形态和任务场景下的泛化能力。
ABot-M0 基于全球开源资源,整合超过 600 万条真实操作轨迹,构建了目前规模最大的通用机器人数据集。通过统一动作表示、坐标系与控制频率,并采用增量式动作建模,实现了跨平台数据融合,支撑了完全基于公开数据的预训练。
算法革新上,ABot-M0 提出了全球首个动作流形学习:有效的机器人动作受限于物理规律、任务目标与环境约束,集中分布在低维结构化的流形上。设计了 AML(Action Manifold Learning) 算法,使模型能够直接预测结构合理、物理可行的动作序列,提升策略的稳定性与解码效率。
为增强空间感知,ABot-M0 引入 3D 感知模块,增强模型对 「前后、远近、遮挡」 等空间语义的理解,在复杂环境中实现更精准的操作决策。
在 Libero、Libero-Plus、RoboCasa 基准测试中,该模型在包含复杂任务组合与动态场景扰动的设定下,平均任务成功率均达到 SOTA。其中,Libero-Plus 基准上达到了 80.5%,较业界先进方案 pi0 提升近 30%,展现了其在高扰动高难度具身操作任务中的领先性能。
ABot-N0
导航是机器人进入物理开放世界的核心基础能力,机器人需要在动态且存在干扰的环境里展现出通用的行动能力,如跨场景送物或跟随服务,这同时也是具身智能演进的终极命题。
然而,当前的具身导航研究普遍深陷 「碎片化」:主流方法往往针对特定任务构建孤立的专用架构,这不仅限制了模型的跨任务泛化能力,更阻碍了智能体从海量异构数据中提取统一物理先验的可能性。
这也是当前机器人常陷于 「环境看不懂、动作做不准」 的核心原因,复杂指令 (如 「去门口帮我看看快递」) 更是难以执行。
高德推出的具身导航基座模型 ABot-N0,以 「全任务一统」 为核心目标,并实现全球首次在单一模型中完整集成 Point-Goal(点位导航)、Object-Goal(目标导航)、Instruction-Following(指令跟随)、POI-Goal(兴趣点导航) 与 Person-Following(人物跟随) 五大导航任务,有效突破了传统架构中任务割裂的瓶颈。
比如,当用户对搭载 ABot-N0 的具身机器人说:「带我去奶茶店买一杯奶茶,再帮我占个座。」 时系统会自动分解为具体的导航任务:首先执行 Point-Goal,根据地图记忆接近奶茶店区域;之后切换至 POI-Goal,精准锁定店铺入口并靠近;随后触发 Instruction-Following,进入店铺并导航至柜台;最后执行 Object-Goal,在店内寻找空沙发并停靠。
相较于只能支持部分任务的具身导航模型,高德 ABot-N0 所实现的五大导航任务给长程复杂任务的执行提供了可行的解决方案。这一能力背后,是高德在架构设计、数据引擎和系统框架上的关键革新。
在模型架构上,ABot-N0 采用层次化的 「大脑‑动作」 设计哲学:由 「认知大脑」 理解指令并做推理,由基于流匹配 (Flow Matching) 的 「动作专家」 生成精确且多峰分布的连续轨迹 。训练上,先让模型做认知训练热身,再用部分认知数据和海量导航动作进行联合监督微调,最后用强化学习把导航决策对齐到人类偏好的行为价值,最终打造出真实环境中更通用的 VLA 基座模型。
在数据侧,依托高德长期沉淀的场景资产和专家示例,高德构建了业内最大规模的具身导航数据引擎,涵盖约 8000 个高保真 3D 场景等海量时空数据与近 1700 万条专家示例,从而增强模型在真实环境中的泛化能力与鲁棒性。
基于 ABot-N0 的系统性创新,其在 CityWalker、SocNav、R2R-CE/RxR-CE、HM3D-OVON、BridgeNav、EVT-Bench 七大权威基准测试中全面刷新了世界纪录。其中在 SocNav 闭环仿真中,成功率 (SR) 飙升 40.5%,在 HM3D-OVON 评测中成功率 (SR) 提升 8.8%,均显著强于之前的 SOTA 模型。
此外,为了解决机器人在执行长程复杂任务时的任务拆解与容错问题,高德提出了可落地的 Agentic Navigation System 具身导航系统框架,行成从 「读懂指令」 到 「长程复杂任务执行」 的闭环能力架构,支持机器人在执行过程中持续感知、记忆、决策与纠错。系统已成功部署于真实四足机器人平台,并在边缘侧实现了高效推理与闭环控制,验证了其在动态现实环境中的泛化性能与工业级稳定性。
【文章来源:techweb】
【TechWeb】2 月 12 日消息,近日,阿里巴巴集团旗下高德正式发布具身操作基座模型 ABot-M0 与具身导航基座模型 ABot-N0,补齐了具身机器人规模化落地的两块核心能力——操作的通用性和导航的长程性,并刷新了全球多项权威评测纪录。
ABot-M0
长期以来,机器人技术的规模化应用面临诸多挑战,其中关键之一在于数据的割裂、动作表示的不统一以及空间理解能力的不足。不同厂商、不同形态的机器人往往使用各自独立的数据体系,导致模型难以跨平台复用,训练效率受限,部署成本高。
高德推出的 ABot-M0 作为一款通用的具身操作基础模型,从 「数据统一—算法革新—空间感知」 三个方面进行了系统性重构,致力于提升模型在多样化机器人形态和任务场景下的泛化能力。
ABot-M0 基于全球开源资源,整合超过 600 万条真实操作轨迹,构建了目前规模最大的通用机器人数据集。通过统一动作表示、坐标系与控制频率,并采用增量式动作建模,实现了跨平台数据融合,支撑了完全基于公开数据的预训练。
算法革新上,ABot-M0 提出了全球首个动作流形学习:有效的机器人动作受限于物理规律、任务目标与环境约束,集中分布在低维结构化的流形上。设计了 AML(Action Manifold Learning) 算法,使模型能够直接预测结构合理、物理可行的动作序列,提升策略的稳定性与解码效率。
为增强空间感知,ABot-M0 引入 3D 感知模块,增强模型对 「前后、远近、遮挡」 等空间语义的理解,在复杂环境中实现更精准的操作决策。
在 Libero、Libero-Plus、RoboCasa 基准测试中,该模型在包含复杂任务组合与动态场景扰动的设定下,平均任务成功率均达到 SOTA。其中,Libero-Plus 基准上达到了 80.5%,较业界先进方案 pi0 提升近 30%,展现了其在高扰动高难度具身操作任务中的领先性能。
ABot-N0
导航是机器人进入物理开放世界的核心基础能力,机器人需要在动态且存在干扰的环境里展现出通用的行动能力,如跨场景送物或跟随服务,这同时也是具身智能演进的终极命题。
然而,当前的具身导航研究普遍深陷 「碎片化」:主流方法往往针对特定任务构建孤立的专用架构,这不仅限制了模型的跨任务泛化能力,更阻碍了智能体从海量异构数据中提取统一物理先验的可能性。
这也是当前机器人常陷于 「环境看不懂、动作做不准」 的核心原因,复杂指令 (如 「去门口帮我看看快递」) 更是难以执行。
高德推出的具身导航基座模型 ABot-N0,以 「全任务一统」 为核心目标,并实现全球首次在单一模型中完整集成 Point-Goal(点位导航)、Object-Goal(目标导航)、Instruction-Following(指令跟随)、POI-Goal(兴趣点导航) 与 Person-Following(人物跟随) 五大导航任务,有效突破了传统架构中任务割裂的瓶颈。
比如,当用户对搭载 ABot-N0 的具身机器人说:「带我去奶茶店买一杯奶茶,再帮我占个座。」 时系统会自动分解为具体的导航任务:首先执行 Point-Goal,根据地图记忆接近奶茶店区域;之后切换至 POI-Goal,精准锁定店铺入口并靠近;随后触发 Instruction-Following,进入店铺并导航至柜台;最后执行 Object-Goal,在店内寻找空沙发并停靠。
相较于只能支持部分任务的具身导航模型,高德 ABot-N0 所实现的五大导航任务给长程复杂任务的执行提供了可行的解决方案。这一能力背后,是高德在架构设计、数据引擎和系统框架上的关键革新。
在模型架构上,ABot-N0 采用层次化的 「大脑‑动作」 设计哲学:由 「认知大脑」 理解指令并做推理,由基于流匹配 (Flow Matching) 的 「动作专家」 生成精确且多峰分布的连续轨迹 。训练上,先让模型做认知训练热身,再用部分认知数据和海量导航动作进行联合监督微调,最后用强化学习把导航决策对齐到人类偏好的行为价值,最终打造出真实环境中更通用的 VLA 基座模型。
在数据侧,依托高德长期沉淀的场景资产和专家示例,高德构建了业内最大规模的具身导航数据引擎,涵盖约 8000 个高保真 3D 场景等海量时空数据与近 1700 万条专家示例,从而增强模型在真实环境中的泛化能力与鲁棒性。
基于 ABot-N0 的系统性创新,其在 CityWalker、SocNav、R2R-CE/RxR-CE、HM3D-OVON、BridgeNav、EVT-Bench 七大权威基准测试中全面刷新了世界纪录。其中在 SocNav 闭环仿真中,成功率 (SR) 飙升 40.5%,在 HM3D-OVON 评测中成功率 (SR) 提升 8.8%,均显著强于之前的 SOTA 模型。
此外,为了解决机器人在执行长程复杂任务时的任务拆解与容错问题,高德提出了可落地的 Agentic Navigation System 具身导航系统框架,行成从 「读懂指令」 到 「长程复杂任务执行」 的闭环能力架构,支持机器人在执行过程中持续感知、记忆、决策与纠错。系统已成功部署于真实四足机器人平台,并在边缘侧实现了高效推理与闭环控制,验证了其在动态现实环境中的泛化性能与工业级稳定性。
