


来源:
上观新闻
犹记蛇年春节,爆火的 DeepSeek,一度把国内其他大模型 「整抑郁」 了。今年,互联网大厂和国产大模型公司无不期待复刻 DeepSeek 的奇迹,赶在春节前密集官宣上新,将新年作为最佳练兵场。
2 月 12 日,上海大模型企业 MiniMax 在 MiniMax Agent 正式上线新一代文本模型 MiniMax M2.5(以下简称 「M2.5」),并于 2 月 13 日全球开源,支持本地化部署。随后,全球用户迅速在 MiniMax Agent 上构建 1 万多个 「专家」,且数量仍在快速增长。
M2.5 被称 「王炸」,在于其性能几乎逼平由美国 AI 公司 Anthropic 开发的模型 Claude Opus 4.6,价格却让人目瞪口呆,连当下最火的开源个人 AI 代理项目 OpenClaw 之父彼得·斯坦伯格也忍不住感慨。

OpenClaw 之父彼得·斯坦伯格转发和评价 M2.5,性能比肩 Claude Opus 4.6,价格便宜 20 倍。
M2.5 定位为 「原生 Agent 生产级模型」 的产品,能自动写代码、调用工具、分析数据、生成报告。
在编程最硬核的 SWE-Bench Verified 榜单上,M2.5 拿到了 80.2% 的高分,与 Claude Opus 4.6 仅有微弱差距。在多语言任务 Multi-SWE-Bench 上,M2.5 超越 Claude Opus 4.6 拿到第一。
针对办公场景,M2.5 在 Word、PPT、Excel、金融建模等高阶场景中能力出众,在测评框架 GDPval-MM 与主流模型的对比中,取得了 59% 的平均胜率。M2.5 生成的表格,能将封面、数据源和详细数据分得清清楚楚,格式规整,仿佛出自强迫症员工之手。
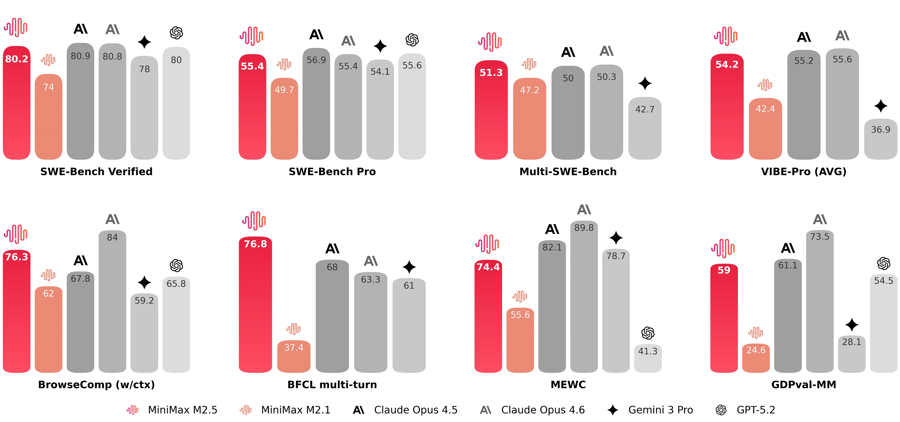
M2.5 对标美国主流模型毫不逊色。
关键在于,能干 「重活」 的 M2.5,其激活的参数量仅 10B,在全球同类第一梯队旗舰模型中 「体型」 最小。
「脑子好使」 的同时,M2.5 的杀手锏,还在于解决了模型 「贵」 和 「慢」 两大痛点。
M2.5 将推理速度干到了 100TPS(每秒事务数),是主流模型的约两倍;输入价格约 0.3 美元/百万 Token(模型输入、输出基本单位),输出约 2.4 美元/百万 Token。按每秒输出 100Token 计算,1 美元就能让智能体连续工作一小时,堪称 「白菜价」。
在算力短缺的时代,能以颠覆式创新实现模型不降智、不卡顿、体验优,是 MiniMax 得以持续留在大模型决赛圈牌桌上的核心王牌。
有意思的是,较 MiniMax 早一天在港交所上市的智谱 AI,也在近期发布智谱 GLM-5,同样对标 Claude Opus 4.6。Claude Opus 4.6 可谓受到了中国一南一北两大模型的夹击。
智谱 GLM-5 在编程和智能体能力上取得了开源模型佳绩。有开发者使用后认为,GLM-5 在真实编程场景的使用体验已逼近 Claude 最强模型,而 Claude 的编程能力在业内处于第一梯队。在全球权威的 Artificial Analysis 榜单中,GLM-5 位居全球第四、开源第一。
智谱将 GLM-5 形容为 「系统架构师」,也就是说,AI 大模型未来不再只满足于写代码完成某一项功能,而是要像工程师一样建构系统,甚至将功能任务分配给不同智能体完成。
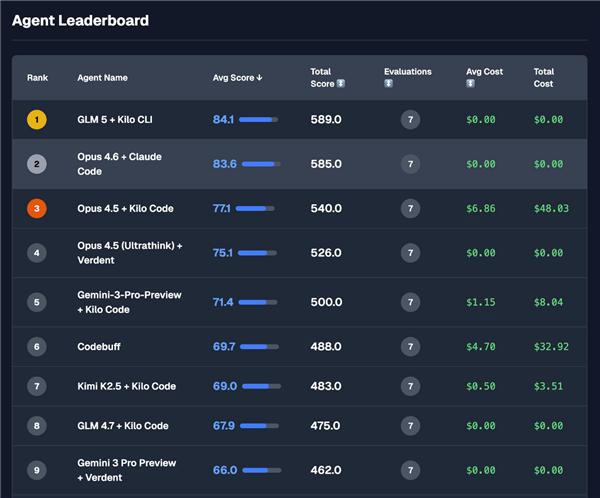
在代理编程测试上,智谱 GLM-5 略胜 Claude 一筹。
另外,千问也在 2 月 10 日发布了新款图像生成模型 Qwen-Image 2.0,支持 1000 个词元的超长指令,同时推理能力也更强。
几乎同一时间,字节跳动也发布了同类模型 Seedream 5.0,文生图能力再次跨前一步。「以前用 AI 生成图像有一个缺陷,受限于推理能力,图片中的汉字经常 『牛头不对马嘴』 或者直接乱码。」 千问开发团队告诉记者,随着指令理解和推理能力的增强,AI 图片生成的 「汉字难题」 将成为历史。
除了文生图、文生视频等多模态模型之外,最基础的大语言模型也 「大有进步」。近日,DeepSeek 悄然上线了一款新模型,虽然并非是万众期待的 V4,但同样令人惊喜。
这款更新模型虽然不具备多模态识别能力,但将上下文处理能力提升至 100 万词元,相当于可以一次性阅读理解全套 《三体》 共计约 90 万字。一名智能体开发者告诉记者:「目前支持上下文理解百万级词元的模型不多,比如谷歌的 Gemini 和 Anthropic 的 Claude,DeepSeek 这次更新也算是 『上车』 了。」
据了解,这一波大模型 「上新潮」 远未停止,豆包 2.0、千问 3.5 等旗舰模型将于近期发布。

(上观新闻)
文章转载自东方财富

