
当地时间周二 (2 月 17 日),Meta 和英伟达宣布,两家美国科技巨头建立了新的长期合作伙伴关系,涵盖本地部署、云和人工智能(AI) 基础设施。

新闻稿写道,Meta 将构建针对训练和推理进行优化的超大规模数据中心,以支持公司长期的 AI 基础设施路线图。
此次合作将实现数百万枚 Blackwell 和 Rubin GPU,以及英伟达的 Grace CPU 的大规模部署,英伟达 Spectrum-X 以太网交换机也将集成到 Facebook 的开放式交换系统平台中。
声明写道,「此次合作代表了英伟达 Grace 的首次大规模部署,并通过对 CPU 生态系统库的共同设计和软件优化投资,提高了每一代处理器的每瓦性能。」
两家公司还在合作部署英伟达的 Vera CPU,有望在 2027 年实现大规模部署,进一步扩大 Meta 的节能型 AI 计算范围,并推进更广泛的 Arm 软件生态系统。
黄仁勋在新闻稿中表示,「目前还没有哪家公司能像 Meta 一样大规模部署人工智能——将前沿研究与工业级基础设施相结合,为数十亿用户打造全球规模最大的系统。」
「通过 CPU、GPU、网络和软件的深度协同设计,我们将完整的英伟达平台带给 Meta 的研究人员和工程师,助力他们构建下一代人工智能前沿的基础。」
扎克伯格则表示,「我们很高兴能与英伟达扩大合作, 利用其 Vera Rubin 平台构建领先的集群,为全世界每个人提供个人超级智能。」
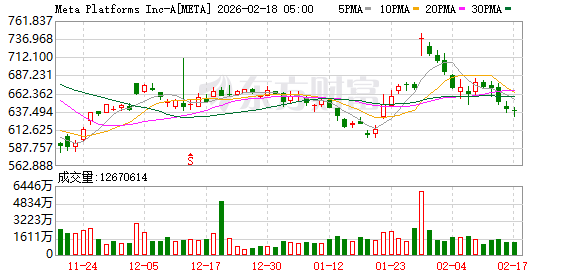
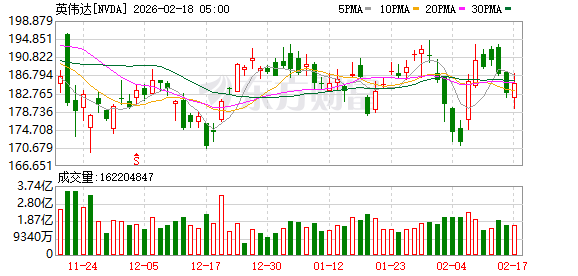
Meta 还在声明中表示,公司将把英伟达的安全技术整合到通信应用程序 WhatsApp 的 AI 功能中。消息公布后,Meta 与英伟达股价在盘后交易中上涨,AMD 股价一度跌超 4%。
需要指出的是,两家公司并非首次合作——Meta 使用英伟达 GPU 已超过十年——但此次协议标志着这两家硅谷巨头之间更深层次、更广泛的技术合作。
本次交易中最大的新增亮点是 CPU,Meta 将成为首家在数据中心单独部署 Grace 的公司,而不是将其与 GPU 集成在同一服务器中。
Meta 上月宣布,公司预计今年资本支出最高将达到 1350 亿美元。
当时,芯片分析机构 Creative Strategies 的芯片分析师 Ben Bajarin 就表示:「我们预计 Meta 很大一部分资本开支都会用于英伟达的数据中心扩建。」
Bajarin 称:「这些芯片专门为推理工作负载和智能代理型任务设计。Meta 的大规模采用,验证了英伟达同时布局 CPU 与 GPU 的 『全栈式』 基础设施战略。」
不过,Meta 并未完全依赖英伟达。去年 11 月有消息称,Meta 考虑在 2027 年的数据中心中采用谷歌的张量处理器 (TPU),当时英伟达股价一度下跌 4%。
同时,Meta 也在自研芯片,并使用 AMD 的产品。随着英伟达供应紧张,各大 AI 公司都在寻求 「第二供应商」。

(财联社)
文章转载自 东方财富