


6 月 17 日,MiniMax 发布 M1 系列模型,被定义为 「全球首个开源的大规模混合架构推理模型」。M1 在处理长文本能力上实现突破,成本下降,推理效率数倍于竞争对手。MiniMax 不仅开源模型权重,还提供 API 服务,价格主打性价比。知名数字经济学者盘和林表示,M1 有进步,但商业价值待验证。
每经记者|陈婷 每经编辑|文多
总部位于上海的人工智能独角兽企业 MiniMax 突然放了个大招。
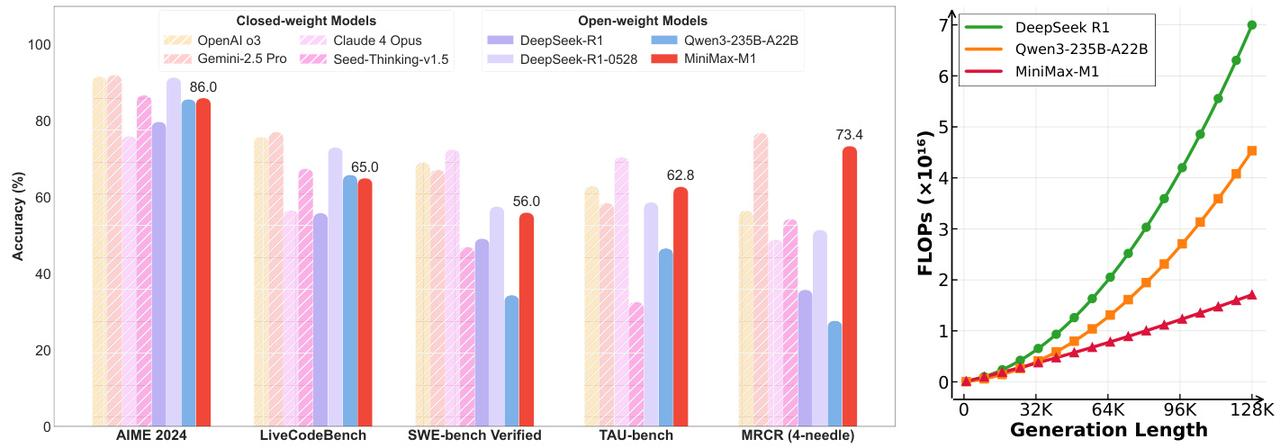
6 月 17 日,MiniMax 正式发布其自主研发的 MiniMax-M1(以下简称 M1) 系列模型。根据 MiniMax 方面的介绍,M1 被定义为 「全球首个开源的大规模混合架构推理模型」。
此外,技术报告显示:M1 模型在处理百万 Token(大模型处理文本时的最小单位) 级长文本的能力方面实现了重大突破,成为上下文最长的推理模型;其 RL(强化训练) 成本下降一个量级,成本仅 53 万美金,推理效率则数倍于竞争对手。
今年开年以来,DeepSeek 持续冲击着大模型行业的格局,接入 DeepSeek-R1 一度被很多企业视为拥抱 AI(人工智能) 的标志。
如今,MiniMax 推出号称具备 「全球最长上下文」 的 M1 模型,有可能后来者居上吗?
当前上下文最长的推理模型 价格还主打性价比
据了解,MiniMax 不仅开源了模型权重,还提供了 API(应用程序编程接口) 服务,价格主打性价比。
其定价策略为:
在 0~3.2 万 (含)Token 范围,输入时 0.8 元/百万 Token,输出时 8 元/百万 Token;
在 3.2 万~12.8 万 (含)Token 范围,输入时 1.2 元/百万 Token,输出时 16 元/百万 Token;
在 12.8 万~100 万 Token 范围,输入时 2.4 元/百万 Token,输出时在 24 元/百万 Token。
据介绍,前两个档位的定价均低于 DeepSeek-R1,而第三个超长文本档位则是该模型目前尚未覆盖的领域。此外,MiniMax 宣布,在其自有的 App(应用程序) 和 Web(网络) 端,M1 模型将保持不限量免费使用。
此外,在长文本能力上,M1 模型原生支持高达 100 万 Token 的上下文窗口,这一数字与谷歌最新的 Gemini 2.5 Pro 持平,是 DeepSeek-R1(12.8 万 Token) 的近 8 倍。同时,它还支持业内最长的 8 万 Token 推理输出。
图片来源:开源技术报告截图
MiniMax 方面表示,实现这一突破的关键在于独创的 「Lightning Attention」 混合构架。传统的 「Transformer」 模型在处理长序列时,注意力机制的计算量会随序列长度呈平方级增长,成为制约性能和成本的主要瓶颈。M1 的混合架构,特别是注意力机制,能够显著优化长下文输入的计算效率。
就这一模型,知名数字经济学者、工信部信息通信经济专家委员会委员盘和林对 《每日经济新闻》 记者表示,之前大模型采用的 「PPO/GRPO」 裁剪方式有一些缺陷,MiniMax 通过 「CISPO」(Clipped IS-weight Policy Optimization) 对这些缺陷进行了一些优化,其目的还是为了降低训练成本和推理成本。
据记者了解,MiniMax 此次提出的 CISPO 算法是另辟蹊径,它没有采用传统算法中调整 Token 的更新方式,而是通过裁剪重要性采样权重来提升、强化学习的效率、稳定性。
「这是进步,但这个进步是否能够转化为商业价值暂时还不清楚。要看具体工具在应用层面的反馈。」 盘和林说。
值得一提的是,今年 4 月,阿里巴巴开源新一代通义千问模型 Qwen3(以下简称千问 3),参数量仅为 DeepSeek-R1 的 1/3,成本大幅下降,据称性能全面超越 DeepSeek-R1、OpenAI o1 等全球顶尖模型。
3 月 16 日,百度正式发布 「文心大模型 4.5」「文心大模型 X1」。据介绍,文心大模型 4.5 是百度首个原生多模态大模型,API 调用价格仅为 GPT-4.5 的 1%。文心大模型 X1 为深度思考模型,性能对标 DeepSeek-R1,调用价格约为其一半。

图片来源:视觉中国-VCG211431510188
大模型还有优化空间,谁找对方向就是下一科技巨头
或许可以说,M1 是 MiniMax 憋了许久的大招之一。
在 DeepSeek 的冲击之下,大模型创业公司今年一开年就面对着战略方向的转折点:是做技术还是做产品?
今年 1 月,MiniMax 创始人兼 CEO 闫俊杰在接受媒体采访时表示,在更明确 「智能水平的提升,没那么依赖很多用户」 后,他做出了取舍,结束了整整半年多的焦虑。闫俊杰明确,现在 MiniMax 最重要的目标不是增长,也不是收入,是 「加速技术迭代」。
同样在 1 月,MiniMax 发布并开源新一代 「01 系列」 模型,包含基础语言大模型 「MiniMax-Text-01」 和视觉多模态大模型 「MiniMax-VL-01」。
到了 3 月,MiniMax 对品牌进行了更清晰的拆分,据悉,MiniMax 将旗下 AI 应用 「海螺 AI」 正式更名为 「MiniMax」,国内版和国际版同步调整。
5 月,MiniMax 发布新一代语音大模型 「Speech-02」。据介绍,基于超强技术与足够泛化的模型能力,Speech-02 为用户带来超拟人、个性化、多样性的语音服务。
虽说在重要性上让步于技术攻坚,但在商业化上,MiniMax 在 B 端 (商业端) 和 C 端 (消费者端) 上皆有布局,对国内市场和海外市场皆有涉猎。
此外,在今年 1 月发布并开源新一代 01 系列模型时,MiniMax 方面便提及,2025 年,AI 将迎来至关重要的发展节点,AI Agent(智能体) 有望成为新一年最重要的产品形态,引领 AI 从传统的 「工具」 角色向更具互动性与协作性的 「伙伴」 角色转变。
当时,MiniMax 便表示:「首先,我们认为这有可能启发更多长上下文的研究和应用,从而更快促进 Agent 时代的到来;第二,开源也能促使我们努力做更多创新,更高质量地开展后续的模型研发工作。」
国泰海通证券在近期的研报中提及,大模型在多模态理解和复杂推理上的突破,为 AI Agent 的发展提供了核心技术支撑。AI 应用虽尚处于落地初期,但未来发展路径明晰,当前处于 B 端萌芽期,未来 C 端有望大规模爆发,最终将实现 B 端与 C 端并行发展,全面推动 AI 产业繁荣。
MiniMax 刚刚推出的 M1 是否能助力其在 AI Agent 这一方向上的发展?对此,盘和林肯定其 「有帮助」,但认为还没有到革命性的程度,属于渐进性算法优化。
早在今年 1 月接受采访时,闫俊杰就明确了技术和产品的关系,他表示,更好的模型可以导向更好的应用,但更好的应用和更多用户并不会导向更好的模型。
在 DeepSeek 火爆全网时,MiniMax 坚持将目标定为 「加速技术迭代」。半年后,MiniMax 终于来到了自己的 「主场时刻」。据记者了解,M1 的发布仅仅是拉开了 MiniMax「开源周」 的序幕。在接下来的 4 个工作日里,MiniMax 计划每天发布一项新技术或产品更新。
就 MiniMax 坚持技术攻坚的前景,盘和林表示,他看好加码大模型的创业公司。盘和林进一步分析说:「现阶段的基础模型依然有很大的提升空间,很多用户并不喜欢用 AI 来干活,因为 AI 不聪明且很慢。之前,有人用所谓的智能体来生成报告,这些智能体却用了数天乃至数周的时间还没有完成,这效率并不比真人高。如今很多人用 AI,也只能解决一部分工作,无法做到直接交付工作的程度。」
在盘和林看来,大模型一定还有优化空间,谁找对了大模型算法优化的方向,谁就是下一个科技巨头。「DeepSeek 向前走了一步,但还不够。」 盘和林说。
封面图片来源:视觉中国-VCG211431510188
文章转载自 每经网

