【文章来源:techweb】
【】12 月 12 日消息,OpenAI 迎来 10 周年之际,一口气官宣多项大事:
1、 发布 GPT-5.2 系列 3 款大模型。GPT‑5.2 系列在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,性能全面碾压谷歌 Gemini 3 Pro 和 Anthropic Claude Opus 4.5。
2、获得迪士尼 10 亿美元投资,双方达成协议,迪士尼成为 Sora 的第一个主要内容授权合作伙伴。

作为这项为期三年的新授权协议的一部分,Sora 将能够生成由用户提示的短视频,供粉丝观看和分享,这些视频将基于迪士尼、漫威、皮克斯和星球大战品牌中超过 200 个动画、面具和生物角色,包括服装、道具、车辆和标志性环境。ChatGPT Images 也将能够将用户的几句话在几秒钟内转化为完整生成的图像。该协议不包括任何人物肖像或声音。
Sora 和 ChatGPT Images 预计将在 2026 年初开始制作迪士尼多品牌授权角色的粉丝视频。
除了许可协议,迪士尼还将成为 OpenAI 的主要客户,使用其 API 构建新产品、工具和体验,包括迪士尼+,并为员工部署 ChatGPT。
OpenAI 创始人 Sam Altman 在 10 周年的公开信中表示:「我从未对我们的研究和产品路线图,以及通向使命的总体视野感到如此乐观。再过十年,我几乎确信我们将建成超级智能。2035 年的人们将能够做到一些我们现在难以轻易想象的事情。」
GPT-5.2 三款模型齐发
OpenAI 推出最新大模型系列 GPT-5.2,将其定位为迄今为止最适合日常专业使用的模型,同时被视为在愈发激烈的代理型 AI 竞争中的关键一步。
GPT-5.2 系列一共 3 款模型,全部上线:
• GPT‑5.2 Instant(即时版) 是一款高效而强大的日常工作与学习 「主力模型」,在信息查询、操作指南、步骤讲解、技术写作以及翻译方面都有显著提升,并延续了 GPT‑5.1 Instant 更温暖、更自然的对话风格。早期测试者特别指出,其解释更清晰,能够在一开始就呈现出关键信息。
• GPT‑5.2 Thinking(思考版) 专为更深入的工作而打造,帮助用户以更高的完成度处理复杂任务,擅长编码、长文档总结、回答上传文件相关问题、逐步推导数学与逻辑问题,以及通过更清晰的结构和更有用的细节支持规划与决策。
• GPT‑5.2 Pro(专业版) 是应对高难度问题时最智能、最可靠的选择,在需要高质量答案的场景中尤为适合。早期测试显示,它的重大错误更少,在编程等复杂领域的表现也更为出色。
GPT-5.2 将从即日起陆续在 ChatGPT 中上线,率先向 ChatGPT Plus、Pro、Go、Business 和 Enterprise 等付费用户开放。

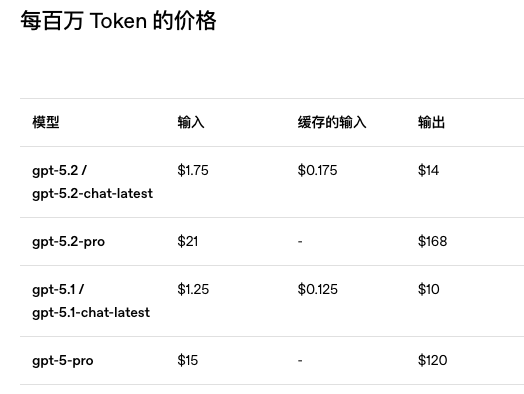
在 API 价格方面,GPT-5.2 的调用价格较上一代上调,输入端 1.75 美元/百万 tokens(约合人民币 12.35 元/百万 tokens)、输出端 14 美元/百万 tokens(约合人民币 98.81 元/百万 tokens)。GPT-5.2 Pro 的定价为 21 美元与 168 美元/百万 tokens(约合人民币 148 元与 1185 元/百万 tokens)。
GPT-5.2 能力碾压 Gemini 3 Pro、超 「专业打工人」
看一下 GPT-5.2 系列的具体性能。
在 OpenAI 公布的 SWE-Bench Pro、GPQA Diamond 等 8 项基准测试中,GPT-5.2 Thinking 的分数均超过谷歌 Gemini 3 Pro 和 Anthropic Claude Opus 4.5。
OpenAI 表示,GPT‑5.2 在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,使其在端到端执行复杂的真实任务时,比以往任何模型都更为出色。
相比 GPT-5.1,GPT-5.2 系列在制作电子表格、构建演示文稿、编写代码、理解长文本、处理图像、调用工具以及执行复杂多步骤任务等方面都有明显提升。该系列模型整体精度更高,幻觉更少,尤其是 Thinking 模型在专业场景下更适合用作高可靠性的智能代理内核。
从 OpenAI 公开的数据来看,GPT‑5.2 在众多基准测试中都刷新了行业水平,包括 GDPval。
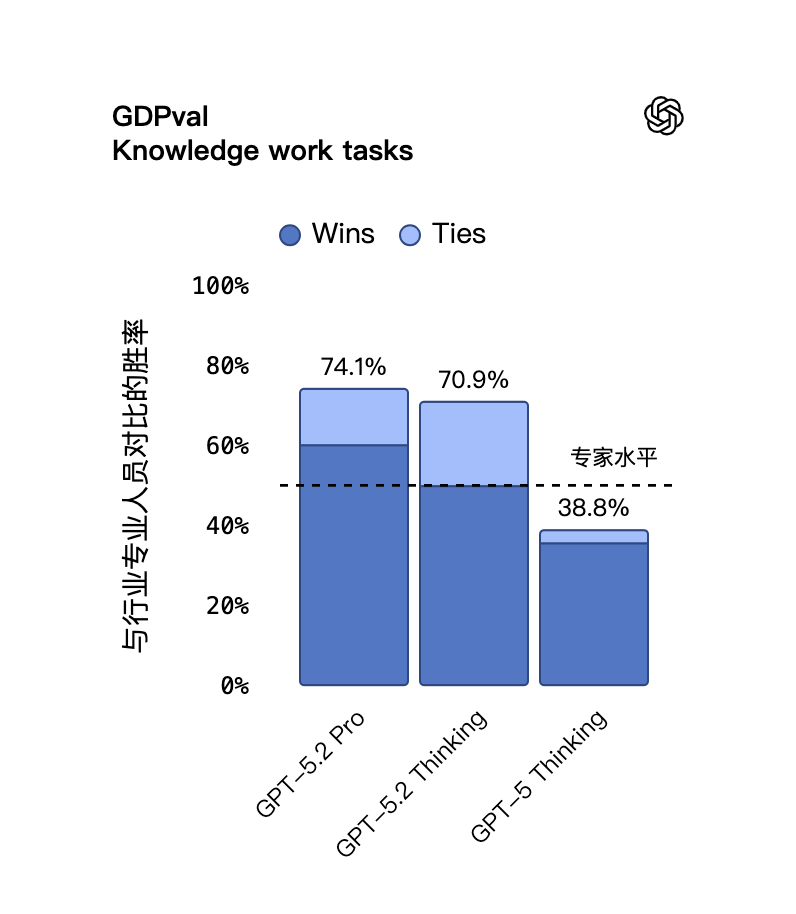
在 GDPval 测试中,模型需要完成定义明确的知识型工作,内容涵盖美国 GDP 贡献度最高的 9 个行业中的 44 种职业。任务要求生成真实的工作成果,例如销售演示文稿、会计表格、急诊排班表、制造业图表或短视频。
在该评测中,GPT‑5.2 Thinking 是首个达到或超过人类专家水平的模型。
根据人类专家评审的结果,GPT‑5.2 Thinking 在 GDPval 的知识型任务中,那些人类专家耗费 4-8 小时完成的任务,有 70.9% 的对比项目表现优于顶尖行业专业人士或与其持平。这些任务包括制作演示文稿、电子表格以及其他专业产出。
同时,GPT‑5.2 Thinking 的输出速度比专家快 11 倍以上,成本却不到人类专家的 1%。
这表明,当与人类监督相结合时,GPT‑5.2 可以有效辅助完成日常由 「白领」 们来做的 「专业工作」。
OpenAI 举例,在针对初级投资银行分析师的内部电子表格建模任务的基准测试中 (例如,为财富 500 强公司制作格式规范、引用完整的三表模型,或为私有化交易构建杠杆收购模型),GPT‑5.2 Thinking 的平均任务得分较 GPT‑5.1 提升了 9.3%,由 59.1% 增至 68.4%。GPT‑5.2 Thinking 生成的电子表格和幻灯片在复杂度与格式呈现上都有明显提升。
编码能力:
GPT-5.2 代表了自 GPT-5 以来在智能体编码上的最大飞跃,并且在同价位中是业界领先的编码模型。
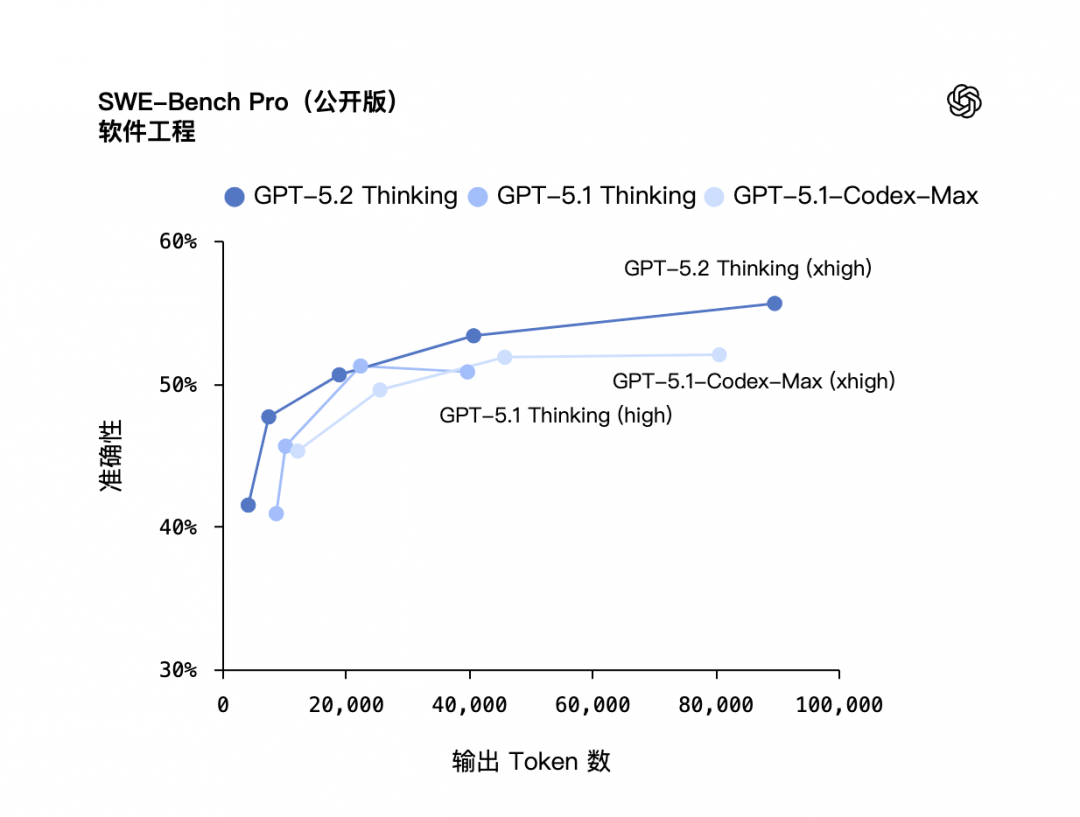
GPT‑5.2 Thinking 在评估真实软件工程能力的基准测试 SWE-bench Pro 取得了 55.6% 的成绩;在 SWEvbench Verified 测试中 GPT‑5.2 Thinking 取得了全新的最高成绩 80%。GPT‑5.2 Thinking 在前端软件工程方面也优于 GPT‑5.1 Thinking。
长文本处理能力:
GPT‑5.2 Thinking 在长上下文推理方面树立了新的技术标杆。OpenAI MRCRv2 是一项用于测试模型整合长文档中分散信息能力的评估,GPT‑5.2 Thinking 在该评估中表现领先。在深度文档分析,如需要跨数十万 Token 关联信息,GPT‑5.2 Thinking 的准确性显著高于 GPT‑5.1 Thinking。在 4-needle MRCR 评测变体 (最长可达 256k Token) 中实现接近 100% 的准确率。
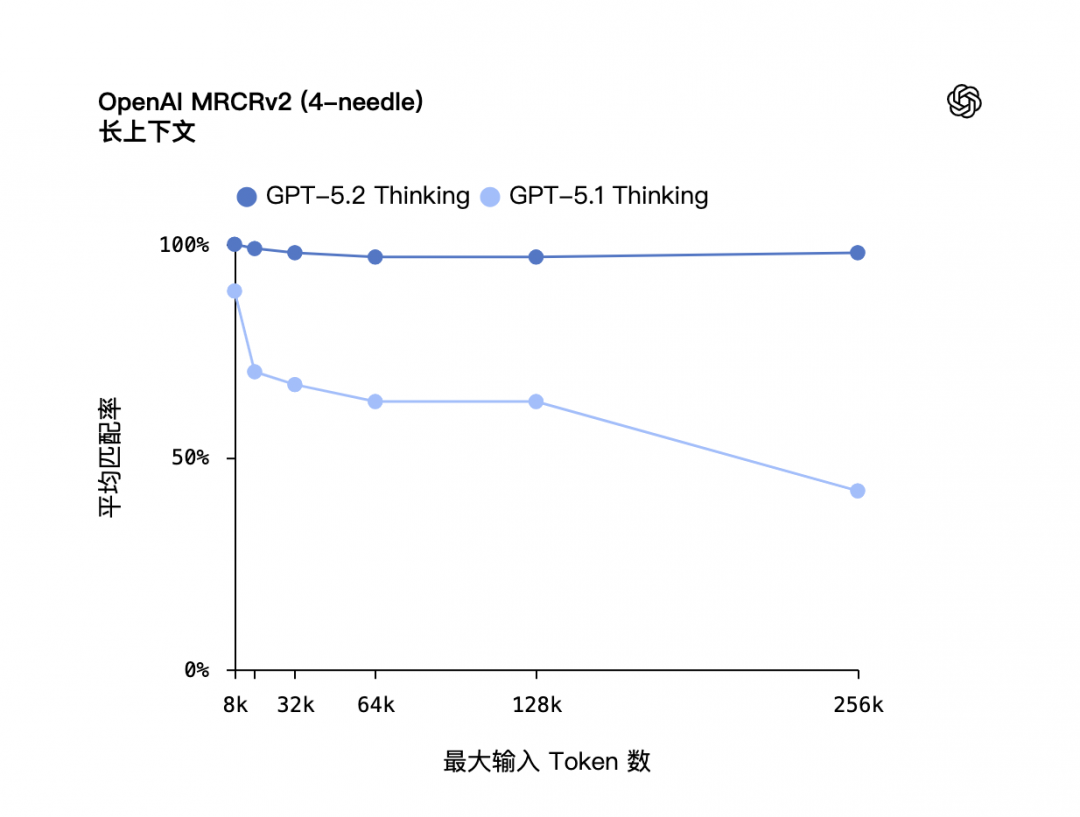
在实际应用中,这让专业人士能够使用 GPT‑5.2 处理长文档,例如报告、合同、研究论文、会议记录和多文件项目,同时在数十万 Token 的范围内保持连贯性和准确性。因此,GPT‑5.2 尤其适合深度分析、信息综合以及复杂的多来源工作流程。
视觉能力:
GPT‑5.2 Thinking 是 OpenAI 目前最强的视觉模型,在图表推理和软件界面理解方面将错误率大幅降低,约减少了一半。
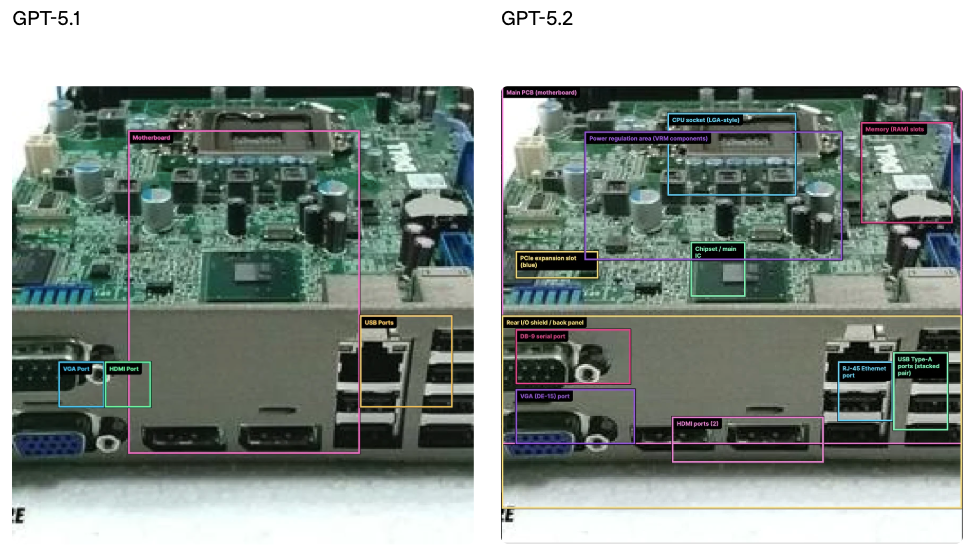
在日常专业场景中,GPT‑5.2 Thinking 能够更准确地理解控制面板、产品截图、技术图示和可视化报告,从而支持金融、运营、工程、设计和客户支持等以视觉信息为核心的工作流程。
工具调用能力:
GPT‑5.2 Thinking 在 Tau2 bench Telecom 测试中取得了 98.7% 的全新优异成绩,展示了它在长程、多轮任务中可靠使用工具的能力。
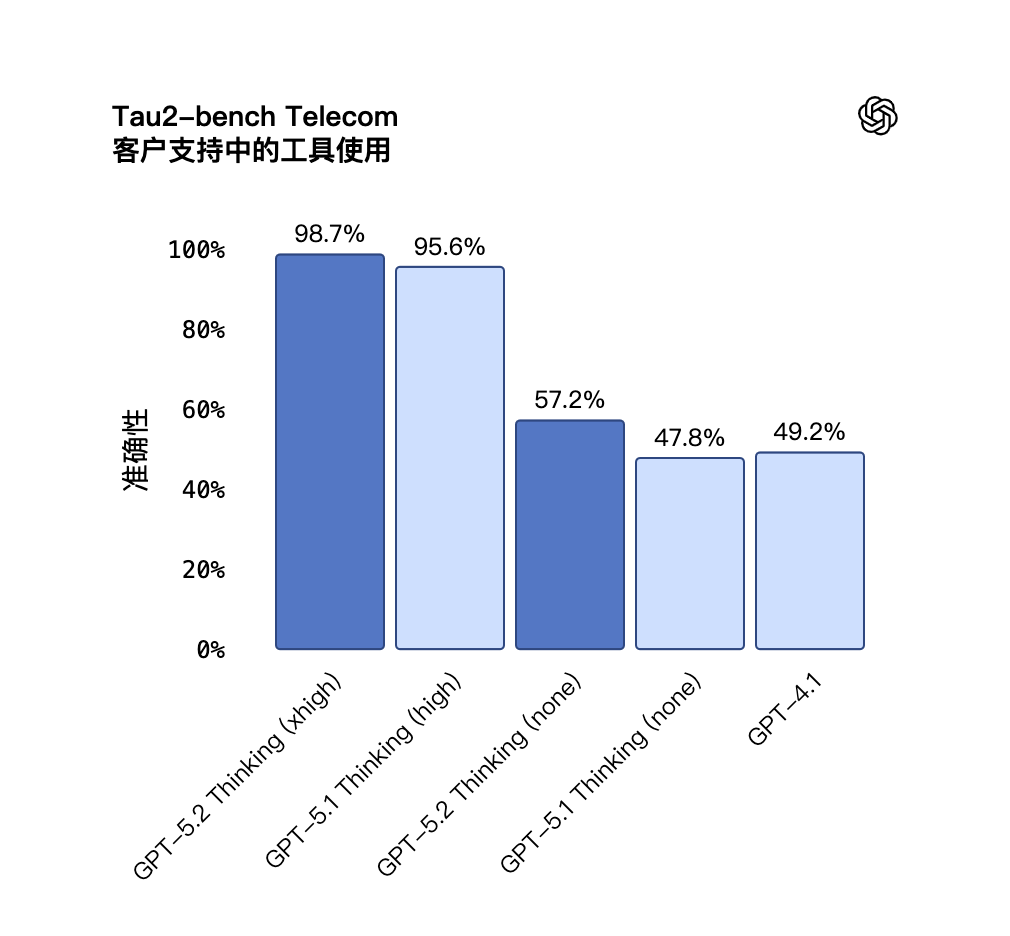
在对延迟敏感的场景中,GPT‑5.2 Thinking 在 reasoning.effort=『none』 模式下也有显著提升,性能大幅领先 GPT‑5.1 和 GPT‑4.1。
这意味着 GPT‑5.2 Thinking 在处理端到端的工作流程更加稳健,例如处理客户支持案例、从多个系统提取数据、执行分析以及生成最终结果,各步骤之间出现中断的情况也会更少。
科学与数学能力:
GPT‑5.2 Pro 和 GPT‑5.2 Thinking 是 OpenAI 目前在科学和数学方面实力最强的模型。
在研究生级防 Google 问答基准测试 GPQA Diamond*中,GPT‑5.2 Pro 取得了 93.2% 的成绩,GPT‑5.2 Thinking 紧随其后,达到 92.4%。
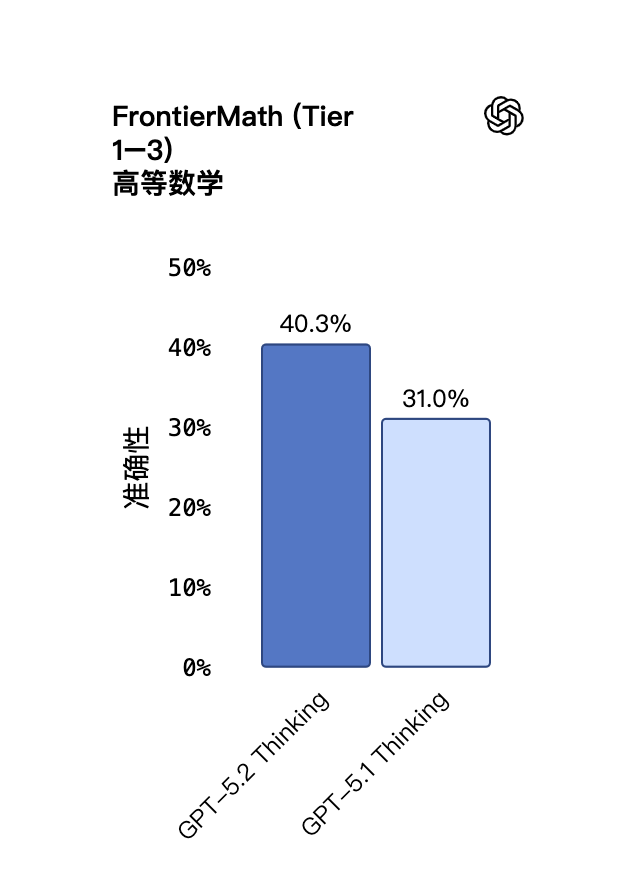
在专家级数学评测 FrontierMath (Tier 1–3) 中,GPT‑5.2 Thinking 树立了新的技术标杆,解决了 40.3% 的问题。
随着 GPT-5.2 大模型的发布,微软董事长兼 CEO Satya Nadella 已在 X 平台上发文宣布,GPT-5.2 将全面进入 Microsoft 365 Copilot、GitHub Copilot 与 Foundry 等产品体系,并作为新的 「默认推理模型」 服务更多工作流场景。(宜月)
【文章来源:techweb】
【】12 月 12 日消息,OpenAI 迎来 10 周年之际,一口气官宣多项大事:
1、 发布 GPT-5.2 系列 3 款大模型。GPT‑5.2 系列在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,性能全面碾压谷歌 Gemini 3 Pro 和 Anthropic Claude Opus 4.5。
2、获得迪士尼 10 亿美元投资,双方达成协议,迪士尼成为 Sora 的第一个主要内容授权合作伙伴。
作为这项为期三年的新授权协议的一部分,Sora 将能够生成由用户提示的短视频,供粉丝观看和分享,这些视频将基于迪士尼、漫威、皮克斯和星球大战品牌中超过 200 个动画、面具和生物角色,包括服装、道具、车辆和标志性环境。ChatGPT Images 也将能够将用户的几句话在几秒钟内转化为完整生成的图像。该协议不包括任何人物肖像或声音。
Sora 和 ChatGPT Images 预计将在 2026 年初开始制作迪士尼多品牌授权角色的粉丝视频。
除了许可协议,迪士尼还将成为 OpenAI 的主要客户,使用其 API 构建新产品、工具和体验,包括迪士尼+,并为员工部署 ChatGPT。
OpenAI 创始人 Sam Altman 在 10 周年的公开信中表示:「我从未对我们的研究和产品路线图,以及通向使命的总体视野感到如此乐观。再过十年,我几乎确信我们将建成超级智能。2035 年的人们将能够做到一些我们现在难以轻易想象的事情。」
GPT-5.2 三款模型齐发
OpenAI 推出最新大模型系列 GPT-5.2,将其定位为迄今为止最适合日常专业使用的模型,同时被视为在愈发激烈的代理型 AI 竞争中的关键一步。
GPT-5.2 系列一共 3 款模型,全部上线:
• GPT‑5.2 Instant(即时版) 是一款高效而强大的日常工作与学习 「主力模型」,在信息查询、操作指南、步骤讲解、技术写作以及翻译方面都有显著提升,并延续了 GPT‑5.1 Instant 更温暖、更自然的对话风格。早期测试者特别指出,其解释更清晰,能够在一开始就呈现出关键信息。
• GPT‑5.2 Thinking(思考版) 专为更深入的工作而打造,帮助用户以更高的完成度处理复杂任务,擅长编码、长文档总结、回答上传文件相关问题、逐步推导数学与逻辑问题,以及通过更清晰的结构和更有用的细节支持规划与决策。
• GPT‑5.2 Pro(专业版) 是应对高难度问题时最智能、最可靠的选择,在需要高质量答案的场景中尤为适合。早期测试显示,它的重大错误更少,在编程等复杂领域的表现也更为出色。
GPT-5.2 将从即日起陆续在 ChatGPT 中上线,率先向 ChatGPT Plus、Pro、Go、Business 和 Enterprise 等付费用户开放。
在 API 价格方面,GPT-5.2 的调用价格较上一代上调,输入端 1.75 美元/百万 tokens(约合人民币 12.35 元/百万 tokens)、输出端 14 美元/百万 tokens(约合人民币 98.81 元/百万 tokens)。GPT-5.2 Pro 的定价为 21 美元与 168 美元/百万 tokens(约合人民币 148 元与 1185 元/百万 tokens)。
GPT-5.2 能力碾压 Gemini 3 Pro、超 「专业打工人」
看一下 GPT-5.2 系列的具体性能。
在 OpenAI 公布的 SWE-Bench Pro、GPQA Diamond 等 8 项基准测试中,GPT-5.2 Thinking 的分数均超过谷歌 Gemini 3 Pro 和 Anthropic Claude Opus 4.5。
OpenAI 表示,GPT‑5.2 在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,使其在端到端执行复杂的真实任务时,比以往任何模型都更为出色。
相比 GPT-5.1,GPT-5.2 系列在制作电子表格、构建演示文稿、编写代码、理解长文本、处理图像、调用工具以及执行复杂多步骤任务等方面都有明显提升。该系列模型整体精度更高,幻觉更少,尤其是 Thinking 模型在专业场景下更适合用作高可靠性的智能代理内核。
从 OpenAI 公开的数据来看,GPT‑5.2 在众多基准测试中都刷新了行业水平,包括 GDPval。
在 GDPval 测试中,模型需要完成定义明确的知识型工作,内容涵盖美国 GDP 贡献度最高的 9 个行业中的 44 种职业。任务要求生成真实的工作成果,例如销售演示文稿、会计表格、急诊排班表、制造业图表或短视频。
在该评测中,GPT‑5.2 Thinking 是首个达到或超过人类专家水平的模型。
根据人类专家评审的结果,GPT‑5.2 Thinking 在 GDPval 的知识型任务中,那些人类专家耗费 4-8 小时完成的任务,有 70.9% 的对比项目表现优于顶尖行业专业人士或与其持平。这些任务包括制作演示文稿、电子表格以及其他专业产出。
同时,GPT‑5.2 Thinking 的输出速度比专家快 11 倍以上,成本却不到人类专家的 1%。
这表明,当与人类监督相结合时,GPT‑5.2 可以有效辅助完成日常由 「白领」 们来做的 「专业工作」。
OpenAI 举例,在针对初级投资银行分析师的内部电子表格建模任务的基准测试中 (例如,为财富 500 强公司制作格式规范、引用完整的三表模型,或为私有化交易构建杠杆收购模型),GPT‑5.2 Thinking 的平均任务得分较 GPT‑5.1 提升了 9.3%,由 59.1% 增至 68.4%。GPT‑5.2 Thinking 生成的电子表格和幻灯片在复杂度与格式呈现上都有明显提升。
编码能力:
GPT-5.2 代表了自 GPT-5 以来在智能体编码上的最大飞跃,并且在同价位中是业界领先的编码模型。
GPT‑5.2 Thinking 在评估真实软件工程能力的基准测试 SWE-bench Pro 取得了 55.6% 的成绩;在 SWEvbench Verified 测试中 GPT‑5.2 Thinking 取得了全新的最高成绩 80%。GPT‑5.2 Thinking 在前端软件工程方面也优于 GPT‑5.1 Thinking。
长文本处理能力:
GPT‑5.2 Thinking 在长上下文推理方面树立了新的技术标杆。OpenAI MRCRv2 是一项用于测试模型整合长文档中分散信息能力的评估,GPT‑5.2 Thinking 在该评估中表现领先。在深度文档分析,如需要跨数十万 Token 关联信息,GPT‑5.2 Thinking 的准确性显著高于 GPT‑5.1 Thinking。在 4-needle MRCR 评测变体 (最长可达 256k Token) 中实现接近 100% 的准确率。
在实际应用中,这让专业人士能够使用 GPT‑5.2 处理长文档,例如报告、合同、研究论文、会议记录和多文件项目,同时在数十万 Token 的范围内保持连贯性和准确性。因此,GPT‑5.2 尤其适合深度分析、信息综合以及复杂的多来源工作流程。
视觉能力:
GPT‑5.2 Thinking 是 OpenAI 目前最强的视觉模型,在图表推理和软件界面理解方面将错误率大幅降低,约减少了一半。
在日常专业场景中,GPT‑5.2 Thinking 能够更准确地理解控制面板、产品截图、技术图示和可视化报告,从而支持金融、运营、工程、设计和客户支持等以视觉信息为核心的工作流程。
工具调用能力:
GPT‑5.2 Thinking 在 Tau2 bench Telecom 测试中取得了 98.7% 的全新优异成绩,展示了它在长程、多轮任务中可靠使用工具的能力。
在对延迟敏感的场景中,GPT‑5.2 Thinking 在 reasoning.effort=『none』 模式下也有显著提升,性能大幅领先 GPT‑5.1 和 GPT‑4.1。
这意味着 GPT‑5.2 Thinking 在处理端到端的工作流程更加稳健,例如处理客户支持案例、从多个系统提取数据、执行分析以及生成最终结果,各步骤之间出现中断的情况也会更少。
科学与数学能力:
GPT‑5.2 Pro 和 GPT‑5.2 Thinking 是 OpenAI 目前在科学和数学方面实力最强的模型。
在研究生级防 Google 问答基准测试 GPQA Diamond*中,GPT‑5.2 Pro 取得了 93.2% 的成绩,GPT‑5.2 Thinking 紧随其后,达到 92.4%。
在专家级数学评测 FrontierMath (Tier 1–3) 中,GPT‑5.2 Thinking 树立了新的技术标杆,解决了 40.3% 的问题。
随着 GPT-5.2 大模型的发布,微软董事长兼 CEO Satya Nadella 已在 X 平台上发文宣布,GPT-5.2 将全面进入 Microsoft 365 Copilot、GitHub Copilot 与 Foundry 等产品体系,并作为新的 「默认推理模型」 服务更多工作流场景。(宜月)
【文章来源:techweb】
【】12 月 12 日消息,OpenAI 迎来 10 周年之际,一口气官宣多项大事:
1、 发布 GPT-5.2 系列 3 款大模型。GPT‑5.2 系列在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,性能全面碾压谷歌 Gemini 3 Pro 和 Anthropic Claude Opus 4.5。
2、获得迪士尼 10 亿美元投资,双方达成协议,迪士尼成为 Sora 的第一个主要内容授权合作伙伴。
作为这项为期三年的新授权协议的一部分,Sora 将能够生成由用户提示的短视频,供粉丝观看和分享,这些视频将基于迪士尼、漫威、皮克斯和星球大战品牌中超过 200 个动画、面具和生物角色,包括服装、道具、车辆和标志性环境。ChatGPT Images 也将能够将用户的几句话在几秒钟内转化为完整生成的图像。该协议不包括任何人物肖像或声音。
Sora 和 ChatGPT Images 预计将在 2026 年初开始制作迪士尼多品牌授权角色的粉丝视频。
除了许可协议,迪士尼还将成为 OpenAI 的主要客户,使用其 API 构建新产品、工具和体验,包括迪士尼+,并为员工部署 ChatGPT。
OpenAI 创始人 Sam Altman 在 10 周年的公开信中表示:「我从未对我们的研究和产品路线图,以及通向使命的总体视野感到如此乐观。再过十年,我几乎确信我们将建成超级智能。2035 年的人们将能够做到一些我们现在难以轻易想象的事情。」
GPT-5.2 三款模型齐发
OpenAI 推出最新大模型系列 GPT-5.2,将其定位为迄今为止最适合日常专业使用的模型,同时被视为在愈发激烈的代理型 AI 竞争中的关键一步。
GPT-5.2 系列一共 3 款模型,全部上线:
• GPT‑5.2 Instant(即时版) 是一款高效而强大的日常工作与学习 「主力模型」,在信息查询、操作指南、步骤讲解、技术写作以及翻译方面都有显著提升,并延续了 GPT‑5.1 Instant 更温暖、更自然的对话风格。早期测试者特别指出,其解释更清晰,能够在一开始就呈现出关键信息。
• GPT‑5.2 Thinking(思考版) 专为更深入的工作而打造,帮助用户以更高的完成度处理复杂任务,擅长编码、长文档总结、回答上传文件相关问题、逐步推导数学与逻辑问题,以及通过更清晰的结构和更有用的细节支持规划与决策。
• GPT‑5.2 Pro(专业版) 是应对高难度问题时最智能、最可靠的选择,在需要高质量答案的场景中尤为适合。早期测试显示,它的重大错误更少,在编程等复杂领域的表现也更为出色。
GPT-5.2 将从即日起陆续在 ChatGPT 中上线,率先向 ChatGPT Plus、Pro、Go、Business 和 Enterprise 等付费用户开放。
在 API 价格方面,GPT-5.2 的调用价格较上一代上调,输入端 1.75 美元/百万 tokens(约合人民币 12.35 元/百万 tokens)、输出端 14 美元/百万 tokens(约合人民币 98.81 元/百万 tokens)。GPT-5.2 Pro 的定价为 21 美元与 168 美元/百万 tokens(约合人民币 148 元与 1185 元/百万 tokens)。
GPT-5.2 能力碾压 Gemini 3 Pro、超 「专业打工人」
看一下 GPT-5.2 系列的具体性能。
在 OpenAI 公布的 SWE-Bench Pro、GPQA Diamond 等 8 项基准测试中,GPT-5.2 Thinking 的分数均超过谷歌 Gemini 3 Pro 和 Anthropic Claude Opus 4.5。
OpenAI 表示,GPT‑5.2 在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,使其在端到端执行复杂的真实任务时,比以往任何模型都更为出色。
相比 GPT-5.1,GPT-5.2 系列在制作电子表格、构建演示文稿、编写代码、理解长文本、处理图像、调用工具以及执行复杂多步骤任务等方面都有明显提升。该系列模型整体精度更高,幻觉更少,尤其是 Thinking 模型在专业场景下更适合用作高可靠性的智能代理内核。
从 OpenAI 公开的数据来看,GPT‑5.2 在众多基准测试中都刷新了行业水平,包括 GDPval。
在 GDPval 测试中,模型需要完成定义明确的知识型工作,内容涵盖美国 GDP 贡献度最高的 9 个行业中的 44 种职业。任务要求生成真实的工作成果,例如销售演示文稿、会计表格、急诊排班表、制造业图表或短视频。
在该评测中,GPT‑5.2 Thinking 是首个达到或超过人类专家水平的模型。
根据人类专家评审的结果,GPT‑5.2 Thinking 在 GDPval 的知识型任务中,那些人类专家耗费 4-8 小时完成的任务,有 70.9% 的对比项目表现优于顶尖行业专业人士或与其持平。这些任务包括制作演示文稿、电子表格以及其他专业产出。
同时,GPT‑5.2 Thinking 的输出速度比专家快 11 倍以上,成本却不到人类专家的 1%。
这表明,当与人类监督相结合时,GPT‑5.2 可以有效辅助完成日常由 「白领」 们来做的 「专业工作」。
OpenAI 举例,在针对初级投资银行分析师的内部电子表格建模任务的基准测试中 (例如,为财富 500 强公司制作格式规范、引用完整的三表模型,或为私有化交易构建杠杆收购模型),GPT‑5.2 Thinking 的平均任务得分较 GPT‑5.1 提升了 9.3%,由 59.1% 增至 68.4%。GPT‑5.2 Thinking 生成的电子表格和幻灯片在复杂度与格式呈现上都有明显提升。
编码能力:
GPT-5.2 代表了自 GPT-5 以来在智能体编码上的最大飞跃,并且在同价位中是业界领先的编码模型。
GPT‑5.2 Thinking 在评估真实软件工程能力的基准测试 SWE-bench Pro 取得了 55.6% 的成绩;在 SWEvbench Verified 测试中 GPT‑5.2 Thinking 取得了全新的最高成绩 80%。GPT‑5.2 Thinking 在前端软件工程方面也优于 GPT‑5.1 Thinking。
长文本处理能力:
GPT‑5.2 Thinking 在长上下文推理方面树立了新的技术标杆。OpenAI MRCRv2 是一项用于测试模型整合长文档中分散信息能力的评估,GPT‑5.2 Thinking 在该评估中表现领先。在深度文档分析,如需要跨数十万 Token 关联信息,GPT‑5.2 Thinking 的准确性显著高于 GPT‑5.1 Thinking。在 4-needle MRCR 评测变体 (最长可达 256k Token) 中实现接近 100% 的准确率。
在实际应用中,这让专业人士能够使用 GPT‑5.2 处理长文档,例如报告、合同、研究论文、会议记录和多文件项目,同时在数十万 Token 的范围内保持连贯性和准确性。因此,GPT‑5.2 尤其适合深度分析、信息综合以及复杂的多来源工作流程。
视觉能力:
GPT‑5.2 Thinking 是 OpenAI 目前最强的视觉模型,在图表推理和软件界面理解方面将错误率大幅降低,约减少了一半。
在日常专业场景中,GPT‑5.2 Thinking 能够更准确地理解控制面板、产品截图、技术图示和可视化报告,从而支持金融、运营、工程、设计和客户支持等以视觉信息为核心的工作流程。
工具调用能力:
GPT‑5.2 Thinking 在 Tau2 bench Telecom 测试中取得了 98.7% 的全新优异成绩,展示了它在长程、多轮任务中可靠使用工具的能力。
在对延迟敏感的场景中,GPT‑5.2 Thinking 在 reasoning.effort=『none』 模式下也有显著提升,性能大幅领先 GPT‑5.1 和 GPT‑4.1。
这意味着 GPT‑5.2 Thinking 在处理端到端的工作流程更加稳健,例如处理客户支持案例、从多个系统提取数据、执行分析以及生成最终结果,各步骤之间出现中断的情况也会更少。
科学与数学能力:
GPT‑5.2 Pro 和 GPT‑5.2 Thinking 是 OpenAI 目前在科学和数学方面实力最强的模型。
在研究生级防 Google 问答基准测试 GPQA Diamond*中,GPT‑5.2 Pro 取得了 93.2% 的成绩,GPT‑5.2 Thinking 紧随其后,达到 92.4%。
在专家级数学评测 FrontierMath (Tier 1–3) 中,GPT‑5.2 Thinking 树立了新的技术标杆,解决了 40.3% 的问题。
随着 GPT-5.2 大模型的发布,微软董事长兼 CEO Satya Nadella 已在 X 平台上发文宣布,GPT-5.2 将全面进入 Microsoft 365 Copilot、GitHub Copilot 与 Foundry 等产品体系,并作为新的 「默认推理模型」 服务更多工作流场景。(宜月)
【文章来源:techweb】
【】12 月 12 日消息,OpenAI 迎来 10 周年之际,一口气官宣多项大事:
1、 发布 GPT-5.2 系列 3 款大模型。GPT‑5.2 系列在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,性能全面碾压谷歌 Gemini 3 Pro 和 Anthropic Claude Opus 4.5。
2、获得迪士尼 10 亿美元投资,双方达成协议,迪士尼成为 Sora 的第一个主要内容授权合作伙伴。
作为这项为期三年的新授权协议的一部分,Sora 将能够生成由用户提示的短视频,供粉丝观看和分享,这些视频将基于迪士尼、漫威、皮克斯和星球大战品牌中超过 200 个动画、面具和生物角色,包括服装、道具、车辆和标志性环境。ChatGPT Images 也将能够将用户的几句话在几秒钟内转化为完整生成的图像。该协议不包括任何人物肖像或声音。
Sora 和 ChatGPT Images 预计将在 2026 年初开始制作迪士尼多品牌授权角色的粉丝视频。
除了许可协议,迪士尼还将成为 OpenAI 的主要客户,使用其 API 构建新产品、工具和体验,包括迪士尼+,并为员工部署 ChatGPT。
OpenAI 创始人 Sam Altman 在 10 周年的公开信中表示:「我从未对我们的研究和产品路线图,以及通向使命的总体视野感到如此乐观。再过十年,我几乎确信我们将建成超级智能。2035 年的人们将能够做到一些我们现在难以轻易想象的事情。」
GPT-5.2 三款模型齐发
OpenAI 推出最新大模型系列 GPT-5.2,将其定位为迄今为止最适合日常专业使用的模型,同时被视为在愈发激烈的代理型 AI 竞争中的关键一步。
GPT-5.2 系列一共 3 款模型,全部上线:
• GPT‑5.2 Instant(即时版) 是一款高效而强大的日常工作与学习 「主力模型」,在信息查询、操作指南、步骤讲解、技术写作以及翻译方面都有显著提升,并延续了 GPT‑5.1 Instant 更温暖、更自然的对话风格。早期测试者特别指出,其解释更清晰,能够在一开始就呈现出关键信息。
• GPT‑5.2 Thinking(思考版) 专为更深入的工作而打造,帮助用户以更高的完成度处理复杂任务,擅长编码、长文档总结、回答上传文件相关问题、逐步推导数学与逻辑问题,以及通过更清晰的结构和更有用的细节支持规划与决策。
• GPT‑5.2 Pro(专业版) 是应对高难度问题时最智能、最可靠的选择,在需要高质量答案的场景中尤为适合。早期测试显示,它的重大错误更少,在编程等复杂领域的表现也更为出色。
GPT-5.2 将从即日起陆续在 ChatGPT 中上线,率先向 ChatGPT Plus、Pro、Go、Business 和 Enterprise 等付费用户开放。
在 API 价格方面,GPT-5.2 的调用价格较上一代上调,输入端 1.75 美元/百万 tokens(约合人民币 12.35 元/百万 tokens)、输出端 14 美元/百万 tokens(约合人民币 98.81 元/百万 tokens)。GPT-5.2 Pro 的定价为 21 美元与 168 美元/百万 tokens(约合人民币 148 元与 1185 元/百万 tokens)。
GPT-5.2 能力碾压 Gemini 3 Pro、超 「专业打工人」
看一下 GPT-5.2 系列的具体性能。
在 OpenAI 公布的 SWE-Bench Pro、GPQA Diamond 等 8 项基准测试中,GPT-5.2 Thinking 的分数均超过谷歌 Gemini 3 Pro 和 Anthropic Claude Opus 4.5。
OpenAI 表示,GPT‑5.2 在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,使其在端到端执行复杂的真实任务时,比以往任何模型都更为出色。
相比 GPT-5.1,GPT-5.2 系列在制作电子表格、构建演示文稿、编写代码、理解长文本、处理图像、调用工具以及执行复杂多步骤任务等方面都有明显提升。该系列模型整体精度更高,幻觉更少,尤其是 Thinking 模型在专业场景下更适合用作高可靠性的智能代理内核。
从 OpenAI 公开的数据来看,GPT‑5.2 在众多基准测试中都刷新了行业水平,包括 GDPval。
在 GDPval 测试中,模型需要完成定义明确的知识型工作,内容涵盖美国 GDP 贡献度最高的 9 个行业中的 44 种职业。任务要求生成真实的工作成果,例如销售演示文稿、会计表格、急诊排班表、制造业图表或短视频。
在该评测中,GPT‑5.2 Thinking 是首个达到或超过人类专家水平的模型。
根据人类专家评审的结果,GPT‑5.2 Thinking 在 GDPval 的知识型任务中,那些人类专家耗费 4-8 小时完成的任务,有 70.9% 的对比项目表现优于顶尖行业专业人士或与其持平。这些任务包括制作演示文稿、电子表格以及其他专业产出。
同时,GPT‑5.2 Thinking 的输出速度比专家快 11 倍以上,成本却不到人类专家的 1%。
这表明,当与人类监督相结合时,GPT‑5.2 可以有效辅助完成日常由 「白领」 们来做的 「专业工作」。
OpenAI 举例,在针对初级投资银行分析师的内部电子表格建模任务的基准测试中 (例如,为财富 500 强公司制作格式规范、引用完整的三表模型,或为私有化交易构建杠杆收购模型),GPT‑5.2 Thinking 的平均任务得分较 GPT‑5.1 提升了 9.3%,由 59.1% 增至 68.4%。GPT‑5.2 Thinking 生成的电子表格和幻灯片在复杂度与格式呈现上都有明显提升。
编码能力:
GPT-5.2 代表了自 GPT-5 以来在智能体编码上的最大飞跃,并且在同价位中是业界领先的编码模型。
GPT‑5.2 Thinking 在评估真实软件工程能力的基准测试 SWE-bench Pro 取得了 55.6% 的成绩;在 SWEvbench Verified 测试中 GPT‑5.2 Thinking 取得了全新的最高成绩 80%。GPT‑5.2 Thinking 在前端软件工程方面也优于 GPT‑5.1 Thinking。
长文本处理能力:
GPT‑5.2 Thinking 在长上下文推理方面树立了新的技术标杆。OpenAI MRCRv2 是一项用于测试模型整合长文档中分散信息能力的评估,GPT‑5.2 Thinking 在该评估中表现领先。在深度文档分析,如需要跨数十万 Token 关联信息,GPT‑5.2 Thinking 的准确性显著高于 GPT‑5.1 Thinking。在 4-needle MRCR 评测变体 (最长可达 256k Token) 中实现接近 100% 的准确率。
在实际应用中,这让专业人士能够使用 GPT‑5.2 处理长文档,例如报告、合同、研究论文、会议记录和多文件项目,同时在数十万 Token 的范围内保持连贯性和准确性。因此,GPT‑5.2 尤其适合深度分析、信息综合以及复杂的多来源工作流程。
视觉能力:
GPT‑5.2 Thinking 是 OpenAI 目前最强的视觉模型,在图表推理和软件界面理解方面将错误率大幅降低,约减少了一半。
在日常专业场景中,GPT‑5.2 Thinking 能够更准确地理解控制面板、产品截图、技术图示和可视化报告,从而支持金融、运营、工程、设计和客户支持等以视觉信息为核心的工作流程。
工具调用能力:
GPT‑5.2 Thinking 在 Tau2 bench Telecom 测试中取得了 98.7% 的全新优异成绩,展示了它在长程、多轮任务中可靠使用工具的能力。
在对延迟敏感的场景中,GPT‑5.2 Thinking 在 reasoning.effort=『none』 模式下也有显著提升,性能大幅领先 GPT‑5.1 和 GPT‑4.1。
这意味着 GPT‑5.2 Thinking 在处理端到端的工作流程更加稳健,例如处理客户支持案例、从多个系统提取数据、执行分析以及生成最终结果,各步骤之间出现中断的情况也会更少。
科学与数学能力:
GPT‑5.2 Pro 和 GPT‑5.2 Thinking 是 OpenAI 目前在科学和数学方面实力最强的模型。
在研究生级防 Google 问答基准测试 GPQA Diamond*中,GPT‑5.2 Pro 取得了 93.2% 的成绩,GPT‑5.2 Thinking 紧随其后,达到 92.4%。
在专家级数学评测 FrontierMath (Tier 1–3) 中,GPT‑5.2 Thinking 树立了新的技术标杆,解决了 40.3% 的问题。
随着 GPT-5.2 大模型的发布,微软董事长兼 CEO Satya Nadella 已在 X 平台上发文宣布,GPT-5.2 将全面进入 Microsoft 365 Copilot、GitHub Copilot 与 Foundry 等产品体系,并作为新的 「默认推理模型」 服务更多工作流场景。(宜月)