


【文章来源:techweb】
【TechWeb】1 月 27 日消息,深度求索 (DeepSeek) 团队发布了论文 《DeepSeek-OCR 2: Visual Causal Flow》 并开源了同名模型 DeepSeek-OCR 2。这一模型是对去年 10 月 20 日发布的 DeepSeek-OCR 模型的升级。
3 个月时间,从 DeepSeek-OCR 到 DeepSeek-OCR 2,论文提到在权威的综合性文档理解基准 OmniDocBench v1.5 上,DeepSeek-OCR 2 取得了 91.09% 的分数,较其前代大幅提升 3.73%。
其核心创新在于提出了 「Visual Causal Flow」 (「视觉因果流」) 这一全新的编码范式。
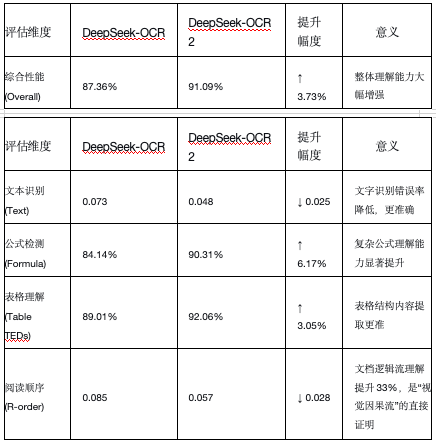
注:R-order 值为模型输出顺序与标准顺序之间的标准化编辑距离,数值越低,说明模型的输出越准确、逻辑顺序越正确。
核心创新:DeepEncoder V2 架构引入 Visual Causal
传统的 OCR(光学字符识别) 技术,往往采取一种近似 「机械扫描」 的策略:将图像切割成网格,然后按照从左到右、从上到下的固定顺序识别文字。这种方式在处理简单文档时有效,但一旦面对充满表格、多栏排版、数学公式或复杂图示的学术论文、报告时,其输出的文本往往逻辑混乱,丢失了内容之间内在的语义关联。
DeepSeek-OCR 2 的研究不再满足于让模型 「看见」 文字,而是致力于让它像人类一样,先 「理解」 文档的视觉结构与内容逻辑,再 「讲述」 出文本。
DeepSeek-OCR 2 引入的 DeepEncoder V2 架构。
从 DeepSeek-OCR 的 DeepEncoder 架构,到 DeepSeek-OCR 2 的 DeepEncoder V2 架构,有了哪些升级?
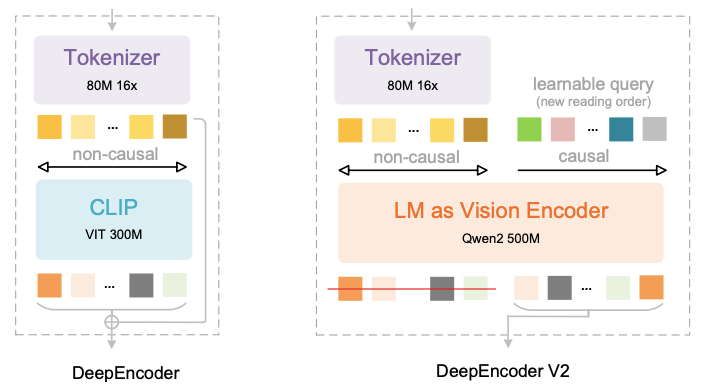
DeepEncoder V2 被设计用于赋予编码器因果推理能力,使其能够在大语言模型进行内容解读之前,智能地对视觉标记进行重排。
DeepEncoder V2 像一位拥有全局观的阅读者。它的工作流程分为三步,实现了认知上的飞跃:
首先,全局观察:模型通过双向注意力机制,无遗漏地 「瞥见」 整页文档的所有视觉信息。
接着,逻辑推理:模型的核心组件——「因果流查询」 开始工作。它不再受制于空间顺序,而是根据内容的语义重要性、排版结构和逻辑关系,动态地推理出一个最合理的 「阅读顺序」。例如,它会先读完一个文本栏,再跳转到旁边的图表标题,然后处理下方的表格,最后识别侧边栏的注释。
最后,有序压缩:模型按照这个自我推理出的逻辑顺序,将高维的视觉信息压缩、重排为一串低维的、富含语义的 「视觉标记」。
这一过程的核心是将空间优先的编码转变为语义优先的编码。论文指出,这种 「因果流」 机制使模型输出的视觉序列本身就携带了强烈的顺序因果性,为后续的语言解码器提供了结构清晰、逻辑通顺的 「思考蓝图」。
从效率到理解的全面突破
基于 「视觉因果流」 这一底层创新,DeepSeek-OCR 2 展现出了一系列显著优于前代及同类模型的能力。
首先,是惊人的处理效率。它仅需 256 至 1120 个视觉标记就能精准表示一页复杂文档的内容,达到了极高的视觉信息压缩率。这极大地减轻了下游大语言模型的计算负担,使得将高质量文档图像理解能力集成到各类 AI 应用中变得更为可行。
其次,在复杂文档理解上实现了质的突破。模型在学术论文、金融报表、杂志等包含多栏、浮动体、数学公式的文档上表现尤为出色。它不仅准确识别文字,更能还原内容间的逻辑顺序,输出后的文本无需大量后期调整即可直接用于分析或归档。
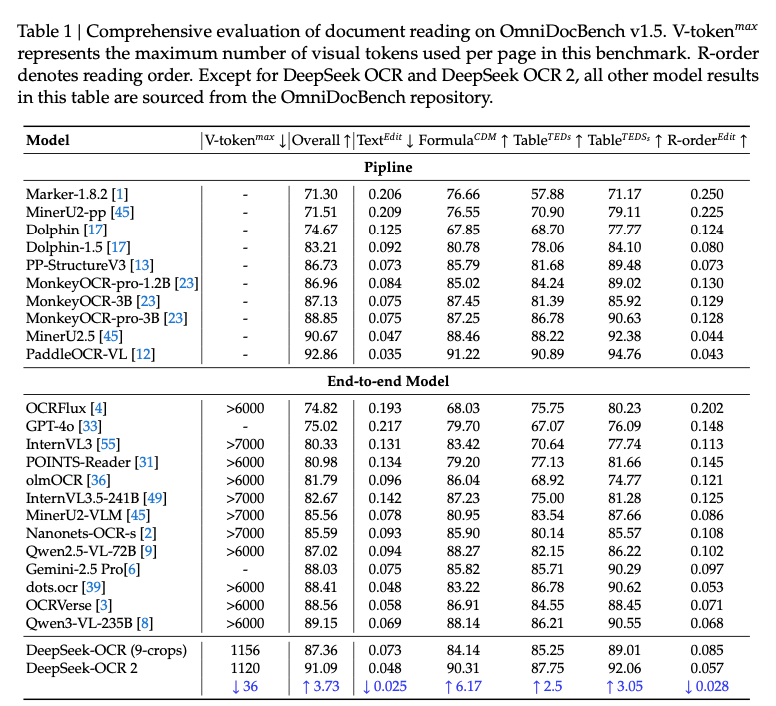
最终,这些优势转化为了硬性的性能提升。在权威的综合性文档理解基准 OmniDocBench v1.5 上,DeepSeek-OCR 2 取得了 91.09% 的分数,较其前代大幅提升 3.73%。更具说服力的是,在衡量阅读顺序准确度的关键指标 (标准化编辑距离) 上,其性能提升了约 33%。在实际生产环境的测试中,模型输出的重复和无意义内容也显著减少,证明了其卓越的稳定性和可靠性。
超越 OCR 的通用模态编码器雏形
DeepSeek-OCR 2 的价值远不止于一个更强大的 OCR 工具。它作为高质量文本数据的生产引擎,可以为大语言模型的训练提供海量、精准的文本语料。更重要的是,它所验证的 「让模型自主决定信息处理顺序」 的 「因果流」 思想,为下一代多模态人工智能架构指明了方向。
论文展望,这一原理有望发展成为一个统一的全模态编码器。未来,无论是文本、图像、音频还是视频,模型都可以先通过类似的 「因果流」 机制,理解该模态信息的内在结构与逻辑,再将其压缩为统一的、富含语义的中间表示,从而实现更深层次、更接近人类认知方式的跨模态理解与生成。
当然,研究也坦诚指出了当前模型的局限,例如在文本极度密集,如古典报纸的场景下,识别效果仍有优化空间。
【文章来源:techweb】
【TechWeb】1 月 27 日消息,深度求索 (DeepSeek) 团队发布了论文 《DeepSeek-OCR 2: Visual Causal Flow》 并开源了同名模型 DeepSeek-OCR 2。这一模型是对去年 10 月 20 日发布的 DeepSeek-OCR 模型的升级。
3 个月时间,从 DeepSeek-OCR 到 DeepSeek-OCR 2,论文提到在权威的综合性文档理解基准 OmniDocBench v1.5 上,DeepSeek-OCR 2 取得了 91.09% 的分数,较其前代大幅提升 3.73%。
其核心创新在于提出了 「Visual Causal Flow」 (「视觉因果流」) 这一全新的编码范式。
注:R-order 值为模型输出顺序与标准顺序之间的标准化编辑距离,数值越低,说明模型的输出越准确、逻辑顺序越正确。
核心创新:DeepEncoder V2 架构引入 Visual Causal
传统的 OCR(光学字符识别) 技术,往往采取一种近似 「机械扫描」 的策略:将图像切割成网格,然后按照从左到右、从上到下的固定顺序识别文字。这种方式在处理简单文档时有效,但一旦面对充满表格、多栏排版、数学公式或复杂图示的学术论文、报告时,其输出的文本往往逻辑混乱,丢失了内容之间内在的语义关联。
DeepSeek-OCR 2 的研究不再满足于让模型 「看见」 文字,而是致力于让它像人类一样,先 「理解」 文档的视觉结构与内容逻辑,再 「讲述」 出文本。
DeepSeek-OCR 2 引入的 DeepEncoder V2 架构。
从 DeepSeek-OCR 的 DeepEncoder 架构,到 DeepSeek-OCR 2 的 DeepEncoder V2 架构,有了哪些升级?
DeepEncoder V2 被设计用于赋予编码器因果推理能力,使其能够在大语言模型进行内容解读之前,智能地对视觉标记进行重排。
DeepEncoder V2 像一位拥有全局观的阅读者。它的工作流程分为三步,实现了认知上的飞跃:
首先,全局观察:模型通过双向注意力机制,无遗漏地 「瞥见」 整页文档的所有视觉信息。
接着,逻辑推理:模型的核心组件——「因果流查询」 开始工作。它不再受制于空间顺序,而是根据内容的语义重要性、排版结构和逻辑关系,动态地推理出一个最合理的 「阅读顺序」。例如,它会先读完一个文本栏,再跳转到旁边的图表标题,然后处理下方的表格,最后识别侧边栏的注释。
最后,有序压缩:模型按照这个自我推理出的逻辑顺序,将高维的视觉信息压缩、重排为一串低维的、富含语义的 「视觉标记」。
这一过程的核心是将空间优先的编码转变为语义优先的编码。论文指出,这种 「因果流」 机制使模型输出的视觉序列本身就携带了强烈的顺序因果性,为后续的语言解码器提供了结构清晰、逻辑通顺的 「思考蓝图」。
从效率到理解的全面突破
基于 「视觉因果流」 这一底层创新,DeepSeek-OCR 2 展现出了一系列显著优于前代及同类模型的能力。
首先,是惊人的处理效率。它仅需 256 至 1120 个视觉标记就能精准表示一页复杂文档的内容,达到了极高的视觉信息压缩率。这极大地减轻了下游大语言模型的计算负担,使得将高质量文档图像理解能力集成到各类 AI 应用中变得更为可行。
其次,在复杂文档理解上实现了质的突破。模型在学术论文、金融报表、杂志等包含多栏、浮动体、数学公式的文档上表现尤为出色。它不仅准确识别文字,更能还原内容间的逻辑顺序,输出后的文本无需大量后期调整即可直接用于分析或归档。
最终,这些优势转化为了硬性的性能提升。在权威的综合性文档理解基准 OmniDocBench v1.5 上,DeepSeek-OCR 2 取得了 91.09% 的分数,较其前代大幅提升 3.73%。更具说服力的是,在衡量阅读顺序准确度的关键指标 (标准化编辑距离) 上,其性能提升了约 33%。在实际生产环境的测试中,模型输出的重复和无意义内容也显著减少,证明了其卓越的稳定性和可靠性。
超越 OCR 的通用模态编码器雏形
DeepSeek-OCR 2 的价值远不止于一个更强大的 OCR 工具。它作为高质量文本数据的生产引擎,可以为大语言模型的训练提供海量、精准的文本语料。更重要的是,它所验证的 「让模型自主决定信息处理顺序」 的 「因果流」 思想,为下一代多模态人工智能架构指明了方向。
论文展望,这一原理有望发展成为一个统一的全模态编码器。未来,无论是文本、图像、音频还是视频,模型都可以先通过类似的 「因果流」 机制,理解该模态信息的内在结构与逻辑,再将其压缩为统一的、富含语义的中间表示,从而实现更深层次、更接近人类认知方式的跨模态理解与生成。
当然,研究也坦诚指出了当前模型的局限,例如在文本极度密集,如古典报纸的场景下,识别效果仍有优化空间。
【文章来源:techweb】
【TechWeb】1 月 27 日消息,深度求索 (DeepSeek) 团队发布了论文 《DeepSeek-OCR 2: Visual Causal Flow》 并开源了同名模型 DeepSeek-OCR 2。这一模型是对去年 10 月 20 日发布的 DeepSeek-OCR 模型的升级。
3 个月时间,从 DeepSeek-OCR 到 DeepSeek-OCR 2,论文提到在权威的综合性文档理解基准 OmniDocBench v1.5 上,DeepSeek-OCR 2 取得了 91.09% 的分数,较其前代大幅提升 3.73%。
其核心创新在于提出了 「Visual Causal Flow」 (「视觉因果流」) 这一全新的编码范式。
注:R-order 值为模型输出顺序与标准顺序之间的标准化编辑距离,数值越低,说明模型的输出越准确、逻辑顺序越正确。
核心创新:DeepEncoder V2 架构引入 Visual Causal
传统的 OCR(光学字符识别) 技术,往往采取一种近似 「机械扫描」 的策略:将图像切割成网格,然后按照从左到右、从上到下的固定顺序识别文字。这种方式在处理简单文档时有效,但一旦面对充满表格、多栏排版、数学公式或复杂图示的学术论文、报告时,其输出的文本往往逻辑混乱,丢失了内容之间内在的语义关联。
DeepSeek-OCR 2 的研究不再满足于让模型 「看见」 文字,而是致力于让它像人类一样,先 「理解」 文档的视觉结构与内容逻辑,再 「讲述」 出文本。
DeepSeek-OCR 2 引入的 DeepEncoder V2 架构。
从 DeepSeek-OCR 的 DeepEncoder 架构,到 DeepSeek-OCR 2 的 DeepEncoder V2 架构,有了哪些升级?
DeepEncoder V2 被设计用于赋予编码器因果推理能力,使其能够在大语言模型进行内容解读之前,智能地对视觉标记进行重排。
DeepEncoder V2 像一位拥有全局观的阅读者。它的工作流程分为三步,实现了认知上的飞跃:
首先,全局观察:模型通过双向注意力机制,无遗漏地 「瞥见」 整页文档的所有视觉信息。
接着,逻辑推理:模型的核心组件——「因果流查询」 开始工作。它不再受制于空间顺序,而是根据内容的语义重要性、排版结构和逻辑关系,动态地推理出一个最合理的 「阅读顺序」。例如,它会先读完一个文本栏,再跳转到旁边的图表标题,然后处理下方的表格,最后识别侧边栏的注释。
最后,有序压缩:模型按照这个自我推理出的逻辑顺序,将高维的视觉信息压缩、重排为一串低维的、富含语义的 「视觉标记」。
这一过程的核心是将空间优先的编码转变为语义优先的编码。论文指出,这种 「因果流」 机制使模型输出的视觉序列本身就携带了强烈的顺序因果性,为后续的语言解码器提供了结构清晰、逻辑通顺的 「思考蓝图」。
从效率到理解的全面突破
基于 「视觉因果流」 这一底层创新,DeepSeek-OCR 2 展现出了一系列显著优于前代及同类模型的能力。
首先,是惊人的处理效率。它仅需 256 至 1120 个视觉标记就能精准表示一页复杂文档的内容,达到了极高的视觉信息压缩率。这极大地减轻了下游大语言模型的计算负担,使得将高质量文档图像理解能力集成到各类 AI 应用中变得更为可行。
其次,在复杂文档理解上实现了质的突破。模型在学术论文、金融报表、杂志等包含多栏、浮动体、数学公式的文档上表现尤为出色。它不仅准确识别文字,更能还原内容间的逻辑顺序,输出后的文本无需大量后期调整即可直接用于分析或归档。
最终,这些优势转化为了硬性的性能提升。在权威的综合性文档理解基准 OmniDocBench v1.5 上,DeepSeek-OCR 2 取得了 91.09% 的分数,较其前代大幅提升 3.73%。更具说服力的是,在衡量阅读顺序准确度的关键指标 (标准化编辑距离) 上,其性能提升了约 33%。在实际生产环境的测试中,模型输出的重复和无意义内容也显著减少,证明了其卓越的稳定性和可靠性。
超越 OCR 的通用模态编码器雏形
DeepSeek-OCR 2 的价值远不止于一个更强大的 OCR 工具。它作为高质量文本数据的生产引擎,可以为大语言模型的训练提供海量、精准的文本语料。更重要的是,它所验证的 「让模型自主决定信息处理顺序」 的 「因果流」 思想,为下一代多模态人工智能架构指明了方向。
论文展望,这一原理有望发展成为一个统一的全模态编码器。未来,无论是文本、图像、音频还是视频,模型都可以先通过类似的 「因果流」 机制,理解该模态信息的内在结构与逻辑,再将其压缩为统一的、富含语义的中间表示,从而实现更深层次、更接近人类认知方式的跨模态理解与生成。
当然,研究也坦诚指出了当前模型的局限,例如在文本极度密集,如古典报纸的场景下,识别效果仍有优化空间。
【文章来源:techweb】
【TechWeb】1 月 27 日消息,深度求索 (DeepSeek) 团队发布了论文 《DeepSeek-OCR 2: Visual Causal Flow》 并开源了同名模型 DeepSeek-OCR 2。这一模型是对去年 10 月 20 日发布的 DeepSeek-OCR 模型的升级。
3 个月时间,从 DeepSeek-OCR 到 DeepSeek-OCR 2,论文提到在权威的综合性文档理解基准 OmniDocBench v1.5 上,DeepSeek-OCR 2 取得了 91.09% 的分数,较其前代大幅提升 3.73%。
其核心创新在于提出了 「Visual Causal Flow」 (「视觉因果流」) 这一全新的编码范式。
注:R-order 值为模型输出顺序与标准顺序之间的标准化编辑距离,数值越低,说明模型的输出越准确、逻辑顺序越正确。
核心创新:DeepEncoder V2 架构引入 Visual Causal
传统的 OCR(光学字符识别) 技术,往往采取一种近似 「机械扫描」 的策略:将图像切割成网格,然后按照从左到右、从上到下的固定顺序识别文字。这种方式在处理简单文档时有效,但一旦面对充满表格、多栏排版、数学公式或复杂图示的学术论文、报告时,其输出的文本往往逻辑混乱,丢失了内容之间内在的语义关联。
DeepSeek-OCR 2 的研究不再满足于让模型 「看见」 文字,而是致力于让它像人类一样,先 「理解」 文档的视觉结构与内容逻辑,再 「讲述」 出文本。
DeepSeek-OCR 2 引入的 DeepEncoder V2 架构。
从 DeepSeek-OCR 的 DeepEncoder 架构,到 DeepSeek-OCR 2 的 DeepEncoder V2 架构,有了哪些升级?
DeepEncoder V2 被设计用于赋予编码器因果推理能力,使其能够在大语言模型进行内容解读之前,智能地对视觉标记进行重排。
DeepEncoder V2 像一位拥有全局观的阅读者。它的工作流程分为三步,实现了认知上的飞跃:
首先,全局观察:模型通过双向注意力机制,无遗漏地 「瞥见」 整页文档的所有视觉信息。
接着,逻辑推理:模型的核心组件——「因果流查询」 开始工作。它不再受制于空间顺序,而是根据内容的语义重要性、排版结构和逻辑关系,动态地推理出一个最合理的 「阅读顺序」。例如,它会先读完一个文本栏,再跳转到旁边的图表标题,然后处理下方的表格,最后识别侧边栏的注释。
最后,有序压缩:模型按照这个自我推理出的逻辑顺序,将高维的视觉信息压缩、重排为一串低维的、富含语义的 「视觉标记」。
这一过程的核心是将空间优先的编码转变为语义优先的编码。论文指出,这种 「因果流」 机制使模型输出的视觉序列本身就携带了强烈的顺序因果性,为后续的语言解码器提供了结构清晰、逻辑通顺的 「思考蓝图」。
从效率到理解的全面突破
基于 「视觉因果流」 这一底层创新,DeepSeek-OCR 2 展现出了一系列显著优于前代及同类模型的能力。
首先,是惊人的处理效率。它仅需 256 至 1120 个视觉标记就能精准表示一页复杂文档的内容,达到了极高的视觉信息压缩率。这极大地减轻了下游大语言模型的计算负担,使得将高质量文档图像理解能力集成到各类 AI 应用中变得更为可行。
其次,在复杂文档理解上实现了质的突破。模型在学术论文、金融报表、杂志等包含多栏、浮动体、数学公式的文档上表现尤为出色。它不仅准确识别文字,更能还原内容间的逻辑顺序,输出后的文本无需大量后期调整即可直接用于分析或归档。
最终,这些优势转化为了硬性的性能提升。在权威的综合性文档理解基准 OmniDocBench v1.5 上,DeepSeek-OCR 2 取得了 91.09% 的分数,较其前代大幅提升 3.73%。更具说服力的是,在衡量阅读顺序准确度的关键指标 (标准化编辑距离) 上,其性能提升了约 33%。在实际生产环境的测试中,模型输出的重复和无意义内容也显著减少,证明了其卓越的稳定性和可靠性。
超越 OCR 的通用模态编码器雏形
DeepSeek-OCR 2 的价值远不止于一个更强大的 OCR 工具。它作为高质量文本数据的生产引擎,可以为大语言模型的训练提供海量、精准的文本语料。更重要的是,它所验证的 「让模型自主决定信息处理顺序」 的 「因果流」 思想,为下一代多模态人工智能架构指明了方向。
论文展望,这一原理有望发展成为一个统一的全模态编码器。未来,无论是文本、图像、音频还是视频,模型都可以先通过类似的 「因果流」 机制,理解该模态信息的内在结构与逻辑,再将其压缩为统一的、富含语义的中间表示,从而实现更深层次、更接近人类认知方式的跨模态理解与生成。
当然,研究也坦诚指出了当前模型的局限,例如在文本极度密集,如古典报纸的场景下,识别效果仍有优化空间。
