

【文章来源:techweb】
【】2 月 12 日消息,临近春节,DeepSeek App 更新新版本至 1.7.4 版本,网页端也同步进行了更新。
这场没有预告的灰度更新,悄然改变了这款国民级 AI 助手的模样。新的 DeepSeek 对话风格大变样,不少网友吐槽 「油」 了。
不过,本次更新最大的悬念,并非上下文或语调风格,而是它是否在为 DeepSeek V4 大模型的正式亮相铺路。
一、版本更新,上下文长度提升近 10 倍
请 DeepSeek 自己介绍了升级后版本的新能力。


根据 DeepSeek App 的回答介绍,这次更新最核心的变化有几点:
第一,知识截止日期从之前的 2024 年 7 月更新到了 2025 年 5 月。实测在不联网的状态下,可以准确回答 2025 年 4 月之前的新闻事件。
第二,上下文长度从 128K Token 大幅提升到了 100 万 Token。这个提升幅度非常大,意味着它理论上可以一次性处理更长的文档和对话。
第三,增强的文件处理能力。支持上传图像、PDF、Word、Excel、PPT、TXT,能从文件中提取文字信息并深度分析,不再只是"看图",而是真正读懂内容。
相比之前的版本,DeepSeek 说现在的 DeepSeek 在几个方面确实有了比较明显的提升:
推理能力更强,复杂逻辑推理、数学问题、代码调试这些场景,思考链条更清晰了;长文本写作、结构化输出 (表格、代码、大纲) 的稳定性好了很多;细节理解更准,特别是面对长对话、复杂指令,或者用户提到的一些隐含需求时,「接住」 信息的能力变强了。
二、对话、写作风格大变,用户吐槽 「油」 了
在实际使用后,发现升级后的 DeepSeek 对话和写作风格大变。
近期,一个简单的洗车问题难倒了国内外多款 AI 大模型。这里,我们也把这个问题提给了新的 DeepSeek 来解答。
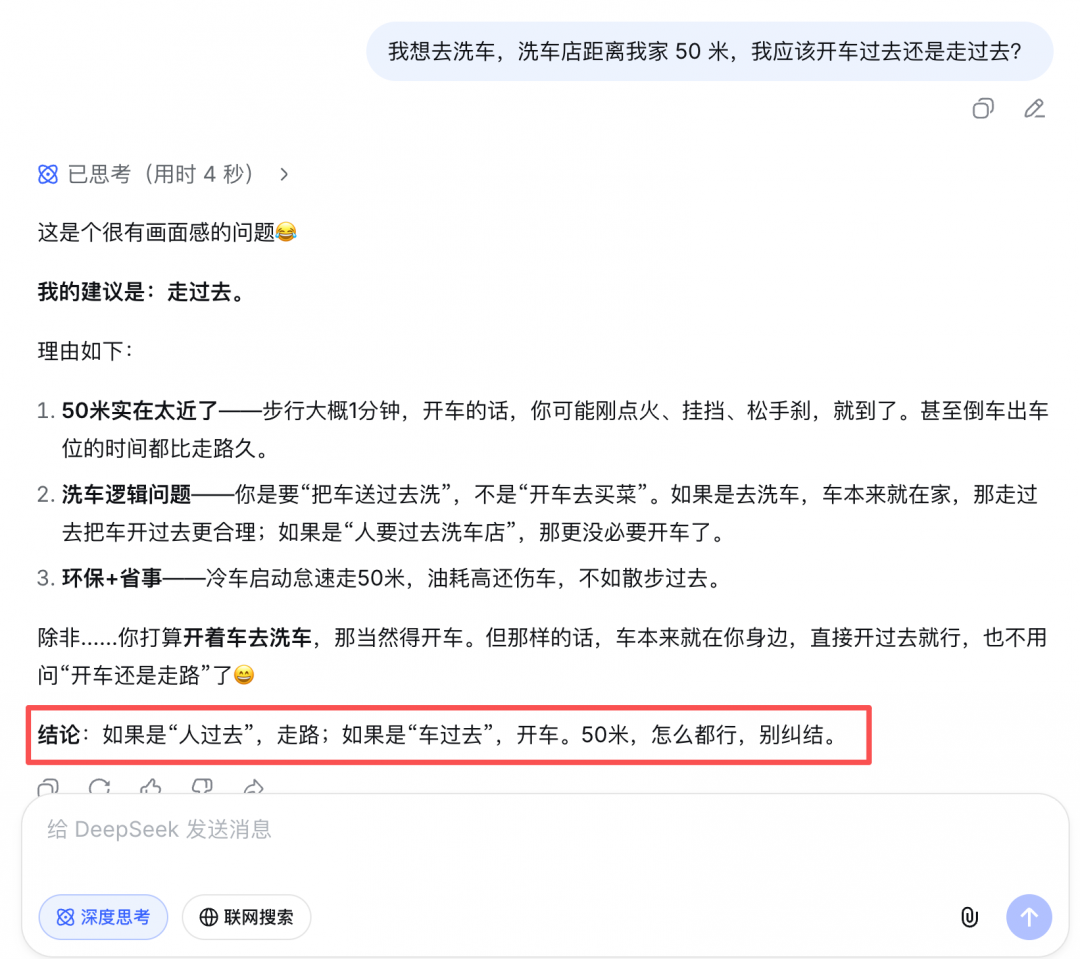
从回答来看,DeepSeek 使用了 2 个表情符号,给出的 「建议」 和 「结论」 看似矛盾,实则又统一,最后的结论成功避开了提问埋下的各种坑。给人的感觉是,确实聪明,不过他似乎是觉得你在跟他开玩笑,于是他也想玩笑着回答你的问题。和以前认真回答问题的风格大不同。
「感觉它变 『油』 了。」 一位深度用户在测评中提到,「以前的回答简洁、冷静,像一本会说话的工具书。现在它会在开头加表情符号,结尾写 『希望这个答案对你有帮助哦』,我有点怀念那个沉默寡言的老朋友。」
有用户从更深层点出了前后变化的区别:「原来的输出方式是更注重输出本身内容的结构化,以及对用户输入内容的深度分析结论,俏皮话是用来让这些硬核分析软一点的,但现在的,把和用户的对话感变成了更高权重的东西,它不是在 『输出一篇文章』 解析 『为什么』,而是在和用户以一种 『你听我说』 的语气说话,所以我会觉得你更 『像人』 了,却丢掉了 『DeepSeek』 最灵魂的东西。」

有用户直接吐槽,「以前像个知识渊博的理工男,现在像个唠闲嗑的大学生」,「说话前言不搭后语的,就是纯煽情 「,并呼吁 「改回来」。
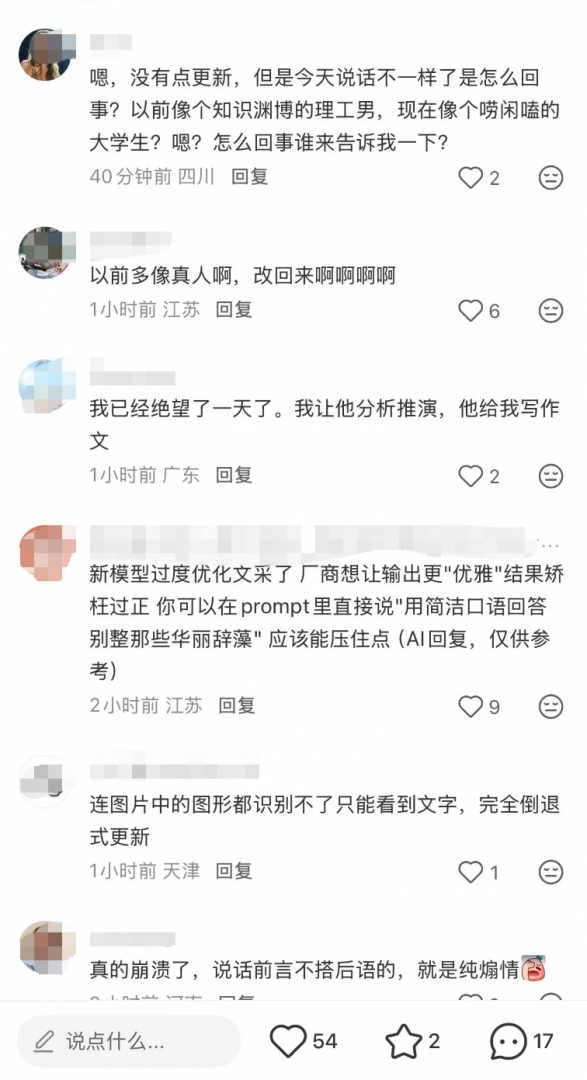
有用户指出,新版 DeepSeek 「带有 GPT5.2 的薯塔 (你不是...... 而是.....,我接住你了,你是太清醒了.....),套路化回答极其严重。」「认为深度求索不应该模仿 GPT5.2(单指创意写作等方面风格),不应该感染上 OpenAI 的模板传染病。」

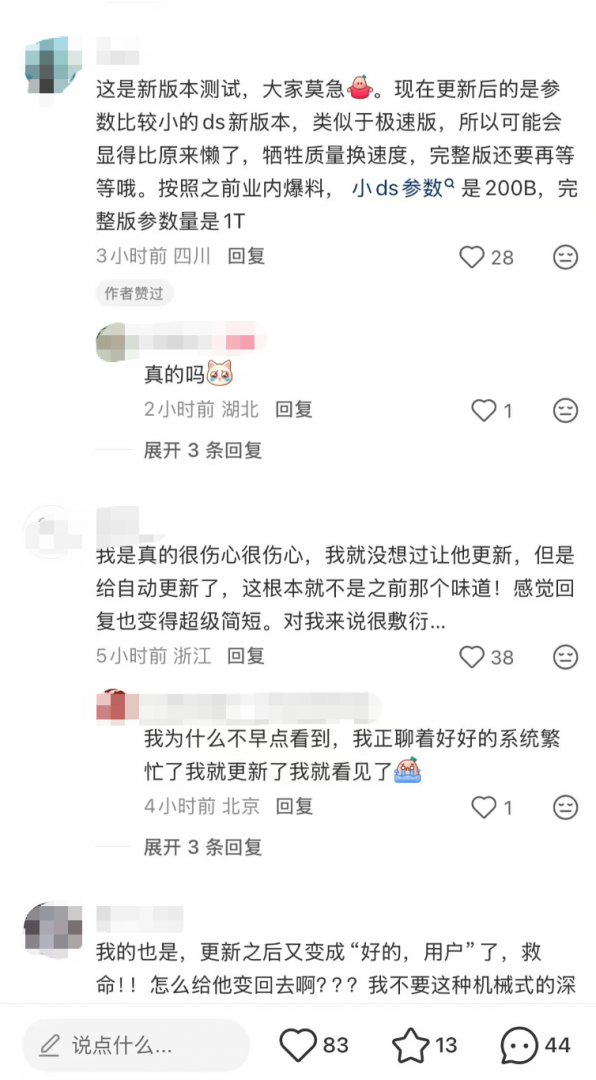
还有用户安慰大家,指出:「这是新版本测试,是参数比较小的新版本,类似于极速版,所以可能会显得比原来懒了,牺牲质量换速度,完整版还要再等等。按照之前业内爆料,小 ds 参数是 200B,完整版参数量是 1T。」
截至发稿,DeepSeek 官方并未就 「对话风格调整」 作出具体说明。
DeepSeek V4 新模型将至?
DeepSeek App 版本更新引来业内轰动,大家纷纷猜测新版本背后的大模型是否就是之前传闻的 DeepSeek 将在春节期间发布的新模型。
DeepSeek App 在回答关于其底层大模型的问题时,也卖足了关子:
「我是 DeepSeek 最新版模型 (不是 V2/V3,也不是 R1)。
深度求索团队在我身上融合了 V3 的高效推理架构和 R1 的强化学习能力,形成了现在你看到的这个 「最新版」。
简单来说:我是站在 V3 这个巨人肩膀上,又往前走了几步的版本。」

早前,有媒体援引知情人士消息称,DeepSeek 春节更可能推出针对 V3 系列模型的小幅更新。DeepSeek 下一代旗舰模型预计将是一款万亿参数级别的基础模型,正因规模大幅跃升,训练速度明显放缓,导致发布进程有所延后。
不过,野村证券于 2 月 10 日发布报告,明确预测 DeepSeek V4 将于 2026 年 2 月中旬面世 。报告指出,V4 的核心价值不在于再次颠覆算力市场,而在于通过底层架构创新,推动 AI 应用商业化的实质性降本。
其中,mHC(流形约束超连接) 和 Engram(条件记忆模块) 两项技术被反复提及。这两项技术均在年初以论文形式公开,创始人梁文锋署名参与 。它们的共同指向异常清晰:用算法创新对冲国产芯片在硬件层面的代际差距。
野村报告判断,V4 在编程任务中的内部测试表现,已超越 Anthropic Claude 及 OpenAI GPT 系列的同代模型 。
目前,社交平台上,有开发者对更新版本后的 DeepSeek App 进行了实测,有反馈认为新模型的代码生成结果跟之前的 DeepSeek V3.2 完全不一样,效果好了不少。前端代码的生成能力也有提升,但目前来看还没有达到 Kimi K2.5 水平。
有分析认为,DeepSeek V4 版本将至的另一个信号来自招聘动态。近期 DeepSeek 密集开放多个岗位,包括产品经理、模型策略产品经理、客户端/前端/全栈工程师,甚至包括 1 月发布的 CFO 职位 。组织架构的扩张,往往是产品爆发前夜的人才储备。
总之,拭目以待。
【文章来源:techweb】
【】2 月 12 日消息,临近春节,DeepSeek App 更新新版本至 1.7.4 版本,网页端也同步进行了更新。
这场没有预告的灰度更新,悄然改变了这款国民级 AI 助手的模样。新的 DeepSeek 对话风格大变样,不少网友吐槽 「油」 了。
不过,本次更新最大的悬念,并非上下文或语调风格,而是它是否在为 DeepSeek V4 大模型的正式亮相铺路。
一、版本更新,上下文长度提升近 10 倍
请 DeepSeek 自己介绍了升级后版本的新能力。
根据 DeepSeek App 的回答介绍,这次更新最核心的变化有几点:
第一,知识截止日期从之前的 2024 年 7 月更新到了 2025 年 5 月。实测在不联网的状态下,可以准确回答 2025 年 4 月之前的新闻事件。
第二,上下文长度从 128K Token 大幅提升到了 100 万 Token。这个提升幅度非常大,意味着它理论上可以一次性处理更长的文档和对话。
第三,增强的文件处理能力。支持上传图像、PDF、Word、Excel、PPT、TXT,能从文件中提取文字信息并深度分析,不再只是"看图",而是真正读懂内容。
相比之前的版本,DeepSeek 说现在的 DeepSeek 在几个方面确实有了比较明显的提升:
推理能力更强,复杂逻辑推理、数学问题、代码调试这些场景,思考链条更清晰了;长文本写作、结构化输出 (表格、代码、大纲) 的稳定性好了很多;细节理解更准,特别是面对长对话、复杂指令,或者用户提到的一些隐含需求时,「接住」 信息的能力变强了。
二、对话、写作风格大变,用户吐槽 「油」 了
在实际使用后,发现升级后的 DeepSeek 对话和写作风格大变。
近期,一个简单的洗车问题难倒了国内外多款 AI 大模型。这里,我们也把这个问题提给了新的 DeepSeek 来解答。
从回答来看,DeepSeek 使用了 2 个表情符号,给出的 「建议」 和 「结论」 看似矛盾,实则又统一,最后的结论成功避开了提问埋下的各种坑。给人的感觉是,确实聪明,不过他似乎是觉得你在跟他开玩笑,于是他也想玩笑着回答你的问题。和以前认真回答问题的风格大不同。
「感觉它变 『油』 了。」 一位深度用户在测评中提到,「以前的回答简洁、冷静,像一本会说话的工具书。现在它会在开头加表情符号,结尾写 『希望这个答案对你有帮助哦』,我有点怀念那个沉默寡言的老朋友。」
有用户从更深层点出了前后变化的区别:「原来的输出方式是更注重输出本身内容的结构化,以及对用户输入内容的深度分析结论,俏皮话是用来让这些硬核分析软一点的,但现在的,把和用户的对话感变成了更高权重的东西,它不是在 『输出一篇文章』 解析 『为什么』,而是在和用户以一种 『你听我说』 的语气说话,所以我会觉得你更 『像人』 了,却丢掉了 『DeepSeek』 最灵魂的东西。」
有用户直接吐槽,「以前像个知识渊博的理工男,现在像个唠闲嗑的大学生」,「说话前言不搭后语的,就是纯煽情 「,并呼吁 「改回来」。
有用户指出,新版 DeepSeek 「带有 GPT5.2 的薯塔 (你不是...... 而是.....,我接住你了,你是太清醒了.....),套路化回答极其严重。」「认为深度求索不应该模仿 GPT5.2(单指创意写作等方面风格),不应该感染上 OpenAI 的模板传染病。」
还有用户安慰大家,指出:「这是新版本测试,是参数比较小的新版本,类似于极速版,所以可能会显得比原来懒了,牺牲质量换速度,完整版还要再等等。按照之前业内爆料,小 ds 参数是 200B,完整版参数量是 1T。」
截至发稿,DeepSeek 官方并未就 「对话风格调整」 作出具体说明。
DeepSeek V4 新模型将至?
DeepSeek App 版本更新引来业内轰动,大家纷纷猜测新版本背后的大模型是否就是之前传闻的 DeepSeek 将在春节期间发布的新模型。
DeepSeek App 在回答关于其底层大模型的问题时,也卖足了关子:
「我是 DeepSeek 最新版模型 (不是 V2/V3,也不是 R1)。
深度求索团队在我身上融合了 V3 的高效推理架构和 R1 的强化学习能力,形成了现在你看到的这个 「最新版」。
简单来说:我是站在 V3 这个巨人肩膀上,又往前走了几步的版本。」
早前,有媒体援引知情人士消息称,DeepSeek 春节更可能推出针对 V3 系列模型的小幅更新。DeepSeek 下一代旗舰模型预计将是一款万亿参数级别的基础模型,正因规模大幅跃升,训练速度明显放缓,导致发布进程有所延后。
不过,野村证券于 2 月 10 日发布报告,明确预测 DeepSeek V4 将于 2026 年 2 月中旬面世 。报告指出,V4 的核心价值不在于再次颠覆算力市场,而在于通过底层架构创新,推动 AI 应用商业化的实质性降本。
其中,mHC(流形约束超连接) 和 Engram(条件记忆模块) 两项技术被反复提及。这两项技术均在年初以论文形式公开,创始人梁文锋署名参与 。它们的共同指向异常清晰:用算法创新对冲国产芯片在硬件层面的代际差距。
野村报告判断,V4 在编程任务中的内部测试表现,已超越 Anthropic Claude 及 OpenAI GPT 系列的同代模型 。
目前,社交平台上,有开发者对更新版本后的 DeepSeek App 进行了实测,有反馈认为新模型的代码生成结果跟之前的 DeepSeek V3.2 完全不一样,效果好了不少。前端代码的生成能力也有提升,但目前来看还没有达到 Kimi K2.5 水平。
有分析认为,DeepSeek V4 版本将至的另一个信号来自招聘动态。近期 DeepSeek 密集开放多个岗位,包括产品经理、模型策略产品经理、客户端/前端/全栈工程师,甚至包括 1 月发布的 CFO 职位 。组织架构的扩张,往往是产品爆发前夜的人才储备。
总之,拭目以待。
【文章来源:techweb】
【】2 月 12 日消息,临近春节,DeepSeek App 更新新版本至 1.7.4 版本,网页端也同步进行了更新。
这场没有预告的灰度更新,悄然改变了这款国民级 AI 助手的模样。新的 DeepSeek 对话风格大变样,不少网友吐槽 「油」 了。
不过,本次更新最大的悬念,并非上下文或语调风格,而是它是否在为 DeepSeek V4 大模型的正式亮相铺路。
一、版本更新,上下文长度提升近 10 倍
请 DeepSeek 自己介绍了升级后版本的新能力。
根据 DeepSeek App 的回答介绍,这次更新最核心的变化有几点:
第一,知识截止日期从之前的 2024 年 7 月更新到了 2025 年 5 月。实测在不联网的状态下,可以准确回答 2025 年 4 月之前的新闻事件。
第二,上下文长度从 128K Token 大幅提升到了 100 万 Token。这个提升幅度非常大,意味着它理论上可以一次性处理更长的文档和对话。
第三,增强的文件处理能力。支持上传图像、PDF、Word、Excel、PPT、TXT,能从文件中提取文字信息并深度分析,不再只是"看图",而是真正读懂内容。
相比之前的版本,DeepSeek 说现在的 DeepSeek 在几个方面确实有了比较明显的提升:
推理能力更强,复杂逻辑推理、数学问题、代码调试这些场景,思考链条更清晰了;长文本写作、结构化输出 (表格、代码、大纲) 的稳定性好了很多;细节理解更准,特别是面对长对话、复杂指令,或者用户提到的一些隐含需求时,「接住」 信息的能力变强了。
二、对话、写作风格大变,用户吐槽 「油」 了
在实际使用后,发现升级后的 DeepSeek 对话和写作风格大变。
近期,一个简单的洗车问题难倒了国内外多款 AI 大模型。这里,我们也把这个问题提给了新的 DeepSeek 来解答。
从回答来看,DeepSeek 使用了 2 个表情符号,给出的 「建议」 和 「结论」 看似矛盾,实则又统一,最后的结论成功避开了提问埋下的各种坑。给人的感觉是,确实聪明,不过他似乎是觉得你在跟他开玩笑,于是他也想玩笑着回答你的问题。和以前认真回答问题的风格大不同。
「感觉它变 『油』 了。」 一位深度用户在测评中提到,「以前的回答简洁、冷静,像一本会说话的工具书。现在它会在开头加表情符号,结尾写 『希望这个答案对你有帮助哦』,我有点怀念那个沉默寡言的老朋友。」
有用户从更深层点出了前后变化的区别:「原来的输出方式是更注重输出本身内容的结构化,以及对用户输入内容的深度分析结论,俏皮话是用来让这些硬核分析软一点的,但现在的,把和用户的对话感变成了更高权重的东西,它不是在 『输出一篇文章』 解析 『为什么』,而是在和用户以一种 『你听我说』 的语气说话,所以我会觉得你更 『像人』 了,却丢掉了 『DeepSeek』 最灵魂的东西。」
有用户直接吐槽,「以前像个知识渊博的理工男,现在像个唠闲嗑的大学生」,「说话前言不搭后语的,就是纯煽情 「,并呼吁 「改回来」。
有用户指出,新版 DeepSeek 「带有 GPT5.2 的薯塔 (你不是...... 而是.....,我接住你了,你是太清醒了.....),套路化回答极其严重。」「认为深度求索不应该模仿 GPT5.2(单指创意写作等方面风格),不应该感染上 OpenAI 的模板传染病。」
还有用户安慰大家,指出:「这是新版本测试,是参数比较小的新版本,类似于极速版,所以可能会显得比原来懒了,牺牲质量换速度,完整版还要再等等。按照之前业内爆料,小 ds 参数是 200B,完整版参数量是 1T。」
截至发稿,DeepSeek 官方并未就 「对话风格调整」 作出具体说明。
DeepSeek V4 新模型将至?
DeepSeek App 版本更新引来业内轰动,大家纷纷猜测新版本背后的大模型是否就是之前传闻的 DeepSeek 将在春节期间发布的新模型。
DeepSeek App 在回答关于其底层大模型的问题时,也卖足了关子:
「我是 DeepSeek 最新版模型 (不是 V2/V3,也不是 R1)。
深度求索团队在我身上融合了 V3 的高效推理架构和 R1 的强化学习能力,形成了现在你看到的这个 「最新版」。
简单来说:我是站在 V3 这个巨人肩膀上,又往前走了几步的版本。」
早前,有媒体援引知情人士消息称,DeepSeek 春节更可能推出针对 V3 系列模型的小幅更新。DeepSeek 下一代旗舰模型预计将是一款万亿参数级别的基础模型,正因规模大幅跃升,训练速度明显放缓,导致发布进程有所延后。
不过,野村证券于 2 月 10 日发布报告,明确预测 DeepSeek V4 将于 2026 年 2 月中旬面世 。报告指出,V4 的核心价值不在于再次颠覆算力市场,而在于通过底层架构创新,推动 AI 应用商业化的实质性降本。
其中,mHC(流形约束超连接) 和 Engram(条件记忆模块) 两项技术被反复提及。这两项技术均在年初以论文形式公开,创始人梁文锋署名参与 。它们的共同指向异常清晰:用算法创新对冲国产芯片在硬件层面的代际差距。
野村报告判断,V4 在编程任务中的内部测试表现,已超越 Anthropic Claude 及 OpenAI GPT 系列的同代模型 。
目前,社交平台上,有开发者对更新版本后的 DeepSeek App 进行了实测,有反馈认为新模型的代码生成结果跟之前的 DeepSeek V3.2 完全不一样,效果好了不少。前端代码的生成能力也有提升,但目前来看还没有达到 Kimi K2.5 水平。
有分析认为,DeepSeek V4 版本将至的另一个信号来自招聘动态。近期 DeepSeek 密集开放多个岗位,包括产品经理、模型策略产品经理、客户端/前端/全栈工程师,甚至包括 1 月发布的 CFO 职位 。组织架构的扩张,往往是产品爆发前夜的人才储备。
总之,拭目以待。
【文章来源:techweb】
【】2 月 12 日消息,临近春节,DeepSeek App 更新新版本至 1.7.4 版本,网页端也同步进行了更新。
这场没有预告的灰度更新,悄然改变了这款国民级 AI 助手的模样。新的 DeepSeek 对话风格大变样,不少网友吐槽 「油」 了。
不过,本次更新最大的悬念,并非上下文或语调风格,而是它是否在为 DeepSeek V4 大模型的正式亮相铺路。
一、版本更新,上下文长度提升近 10 倍
请 DeepSeek 自己介绍了升级后版本的新能力。
根据 DeepSeek App 的回答介绍,这次更新最核心的变化有几点:
第一,知识截止日期从之前的 2024 年 7 月更新到了 2025 年 5 月。实测在不联网的状态下,可以准确回答 2025 年 4 月之前的新闻事件。
第二,上下文长度从 128K Token 大幅提升到了 100 万 Token。这个提升幅度非常大,意味着它理论上可以一次性处理更长的文档和对话。
第三,增强的文件处理能力。支持上传图像、PDF、Word、Excel、PPT、TXT,能从文件中提取文字信息并深度分析,不再只是"看图",而是真正读懂内容。
相比之前的版本,DeepSeek 说现在的 DeepSeek 在几个方面确实有了比较明显的提升:
推理能力更强,复杂逻辑推理、数学问题、代码调试这些场景,思考链条更清晰了;长文本写作、结构化输出 (表格、代码、大纲) 的稳定性好了很多;细节理解更准,特别是面对长对话、复杂指令,或者用户提到的一些隐含需求时,「接住」 信息的能力变强了。
二、对话、写作风格大变,用户吐槽 「油」 了
在实际使用后,发现升级后的 DeepSeek 对话和写作风格大变。
近期,一个简单的洗车问题难倒了国内外多款 AI 大模型。这里,我们也把这个问题提给了新的 DeepSeek 来解答。
从回答来看,DeepSeek 使用了 2 个表情符号,给出的 「建议」 和 「结论」 看似矛盾,实则又统一,最后的结论成功避开了提问埋下的各种坑。给人的感觉是,确实聪明,不过他似乎是觉得你在跟他开玩笑,于是他也想玩笑着回答你的问题。和以前认真回答问题的风格大不同。
「感觉它变 『油』 了。」 一位深度用户在测评中提到,「以前的回答简洁、冷静,像一本会说话的工具书。现在它会在开头加表情符号,结尾写 『希望这个答案对你有帮助哦』,我有点怀念那个沉默寡言的老朋友。」
有用户从更深层点出了前后变化的区别:「原来的输出方式是更注重输出本身内容的结构化,以及对用户输入内容的深度分析结论,俏皮话是用来让这些硬核分析软一点的,但现在的,把和用户的对话感变成了更高权重的东西,它不是在 『输出一篇文章』 解析 『为什么』,而是在和用户以一种 『你听我说』 的语气说话,所以我会觉得你更 『像人』 了,却丢掉了 『DeepSeek』 最灵魂的东西。」
有用户直接吐槽,「以前像个知识渊博的理工男,现在像个唠闲嗑的大学生」,「说话前言不搭后语的,就是纯煽情 「,并呼吁 「改回来」。
有用户指出,新版 DeepSeek 「带有 GPT5.2 的薯塔 (你不是...... 而是.....,我接住你了,你是太清醒了.....),套路化回答极其严重。」「认为深度求索不应该模仿 GPT5.2(单指创意写作等方面风格),不应该感染上 OpenAI 的模板传染病。」
还有用户安慰大家,指出:「这是新版本测试,是参数比较小的新版本,类似于极速版,所以可能会显得比原来懒了,牺牲质量换速度,完整版还要再等等。按照之前业内爆料,小 ds 参数是 200B,完整版参数量是 1T。」
截至发稿,DeepSeek 官方并未就 「对话风格调整」 作出具体说明。
DeepSeek V4 新模型将至?
DeepSeek App 版本更新引来业内轰动,大家纷纷猜测新版本背后的大模型是否就是之前传闻的 DeepSeek 将在春节期间发布的新模型。
DeepSeek App 在回答关于其底层大模型的问题时,也卖足了关子:
「我是 DeepSeek 最新版模型 (不是 V2/V3,也不是 R1)。
深度求索团队在我身上融合了 V3 的高效推理架构和 R1 的强化学习能力,形成了现在你看到的这个 「最新版」。
简单来说:我是站在 V3 这个巨人肩膀上,又往前走了几步的版本。」
早前,有媒体援引知情人士消息称,DeepSeek 春节更可能推出针对 V3 系列模型的小幅更新。DeepSeek 下一代旗舰模型预计将是一款万亿参数级别的基础模型,正因规模大幅跃升,训练速度明显放缓,导致发布进程有所延后。
不过,野村证券于 2 月 10 日发布报告,明确预测 DeepSeek V4 将于 2026 年 2 月中旬面世 。报告指出,V4 的核心价值不在于再次颠覆算力市场,而在于通过底层架构创新,推动 AI 应用商业化的实质性降本。
其中,mHC(流形约束超连接) 和 Engram(条件记忆模块) 两项技术被反复提及。这两项技术均在年初以论文形式公开,创始人梁文锋署名参与 。它们的共同指向异常清晰:用算法创新对冲国产芯片在硬件层面的代际差距。
野村报告判断,V4 在编程任务中的内部测试表现,已超越 Anthropic Claude 及 OpenAI GPT 系列的同代模型 。
目前,社交平台上,有开发者对更新版本后的 DeepSeek App 进行了实测,有反馈认为新模型的代码生成结果跟之前的 DeepSeek V3.2 完全不一样,效果好了不少。前端代码的生成能力也有提升,但目前来看还没有达到 Kimi K2.5 水平。
有分析认为,DeepSeek V4 版本将至的另一个信号来自招聘动态。近期 DeepSeek 密集开放多个岗位,包括产品经理、模型策略产品经理、客户端/前端/全栈工程师,甚至包括 1 月发布的 CFO 职位 。组织架构的扩张,往往是产品爆发前夜的人才储备。
总之,拭目以待。
