【文章来源:techweb】
【TechWeb】1 月 30 日消息,百度在 OCR 领域再发力。
29 日,百度正式发布并开源新一代文档解析模型 PaddleOCR-VL-1.5。
该模型以仅 0.9B 参数的轻量架构,在全球权威文档解析评测榜单 OmniDocBench V1.5 中取得全球综合性能第一成绩,整体精度达到 94.5%,不仅超过 Gemini-3-Pro、Qwen3-VL-235B-A22B、GPT-5.2 等模型,也超过了 1 月 27 日 DeepSeek 刚刚发布和开源的 DeepSeek-OCR2 模型。
目前,PaddleOCR-VL-1.5 已全面开源,开发者可通过 GitHub、Hugging Face 获取,并在 PaddleOCR 官网进行在线体验或通过百度智能云千帆平台调用 API 接口。
在线使用/API:https://www.paddleocr.com
开源项目地址:https://github.com/PaddlePaddle/PaddleOCR
模型下载地址:https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
PaddleOCR-VL-1.5 全球首次实现 「异形框定位」
PaddleOCR-VL-1.5 是 2025 年 10 月 16 日百度首次发布并开源的 PaddleOCR-VL 模型的升级版。
相比于上代,PaddleOCR-VL-1.5-0.9B 继承了轻量级架构,NaViT 视觉编码器 + ERNIE-4.5-0.3B 语言模型。
在功能层面,PaddleOCR-VL-1.5 新增多项能力,包括:
进一步集成印章识别、文本检测与识别等任务能力;
针对特殊场景与多语种识别进行系统优化,在生僻字、古籍文献、多语种表格、下划线与复选框等复杂结构识别方面显著提升;
新增对藏语、孟加拉语等语种的支持;
模型还支持跨页表格自动合并与跨页段落标题识别,有效解决长文档解析中的结构断裂问题。
尤其值得注意的是,PaddleOCR-VL-1.5 全球首次实现 OCR 模型的 「异形框定位」 能力,使机器能够精准识别倾斜、弯折、拍照畸变等非规则文档形态,首次让 「歪文档」 实现稳定、可规模化解析。
该技术解决了传统 OCR 模型在移动拍照、扫描件变形、复杂光照等真实场景中因文档形变导致的识别失败问题,可广泛应用于金融票据处理、档案数字化、政务文档流转等场景。
PaddleOCR-VL-1.5 性能超 DeepSeek-OCR2
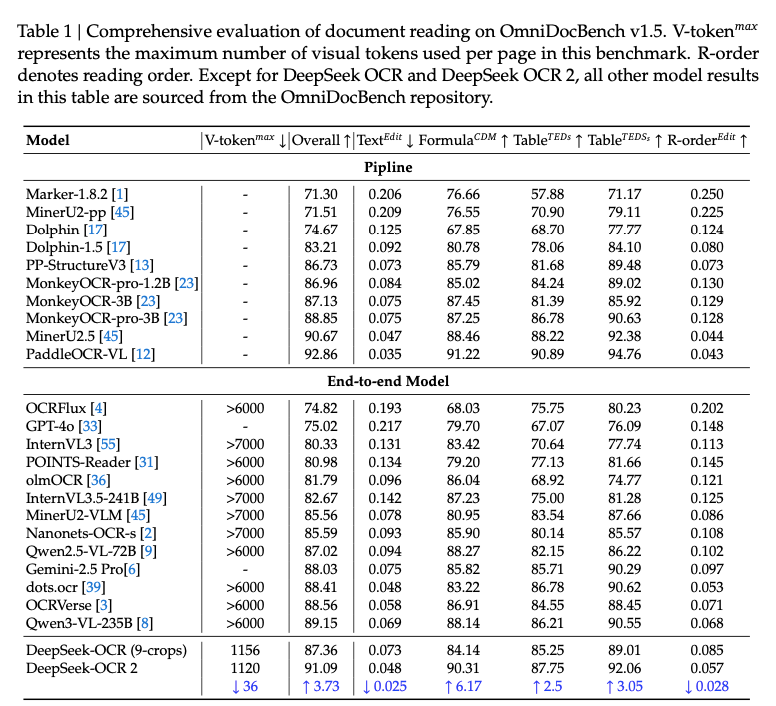
技术文档内容显示,PaddleOCR-VL-1.5 基于文心大模型进行开发,在 OmniDocBench V1.5 文档解析基准上实现了 94.5% 的最新最先进 (SOTA) 准确率,在文本、公式、表格、阅读顺序所有子任务上均领先。
表格来源:PaddleOCR-VL-1.5 技术文档
公式识别 (FormulaCDM):94.21%,大幅领先所有对比模型,显示出在复杂数学表达式解析上的巨大优势。
表格识别 (TableTEDS):92.76%,同样是最高水平,表明其对表格结构的理解能力极强。
文本与阅读顺序:文本识别 (TextEdit: 0.035) 和阅读顺序 (Reading OrderEdit: 0.042) 误差极低,仅为同类其他模型约一半,保持了顶级水准。
PaddleOCR-VL-1.5 在复杂文档结构还原与版面逻辑理解方面具备更高稳定性,在合同、财报等高复杂度业务场景中拥有更高可用性。
1 月 27 日 DeepSeek 刚刚发布和开源的 DeepSeek-OCR 2 模型,在 OmniDocBench V1.5 的综合得分是 91.09%。这也意味着 PaddleOCR-VL-1.5 性能超过 DeepSeek-OCR 2。
表格来源:1 月 27 日 DeepSeek-OCR 2 模型开源技术文档
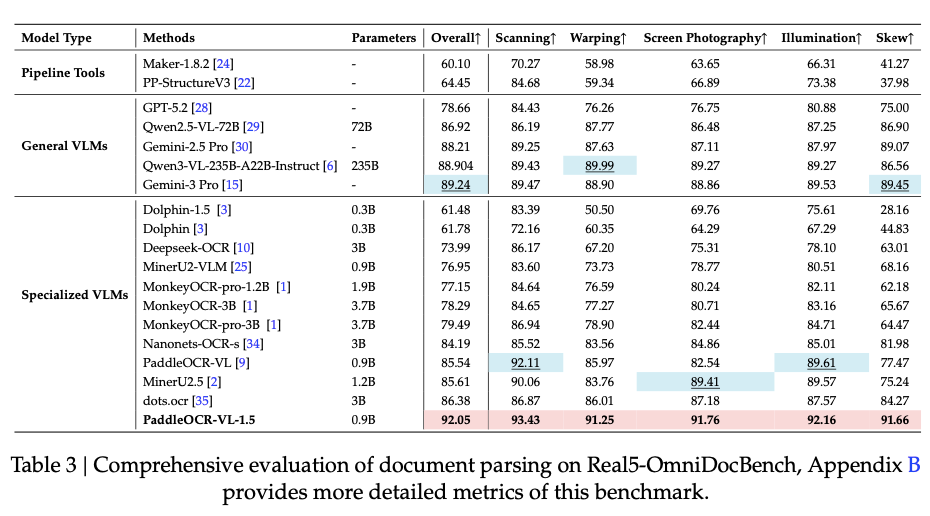
另外,为了严格评估模型对真实世界物理畸变的鲁棒性——包括扫描、倾斜、弯曲、屏幕翻拍和光照不均。百度飞桨团队提出了 Real5-OmniDocBench 评测基准。PaddleOCR-VL-1.5 在该基准上取得 92.05% 的整体精度,同样达到 SOTA,在五个子场景下均排名第一,显著优于包括 Qwen3-VL-235B、Gemini-3 Pro 在内的通用大模型。
表格来源:PaddleOCR-VL-1.5 技术文档
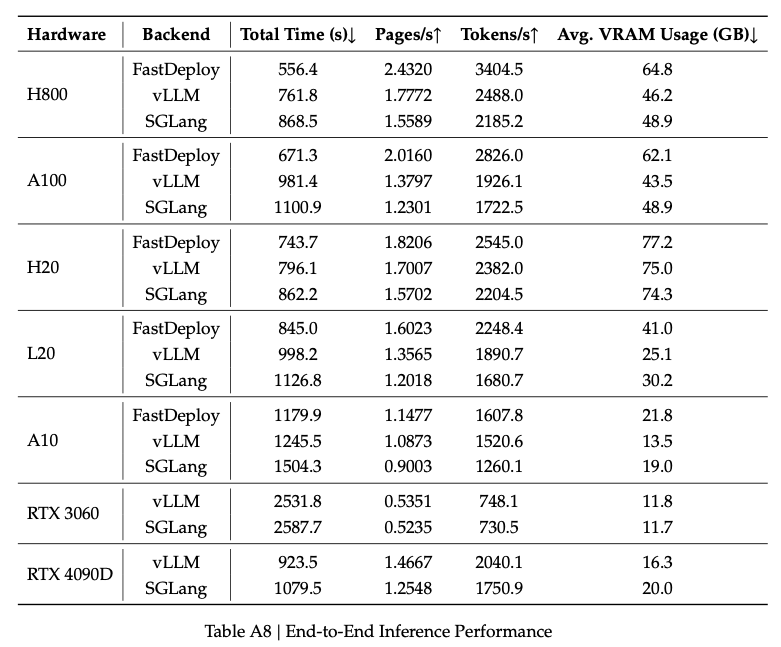
另外,在硬件适配方面,PaddleOCR-VL-1.5 模型在 H800、A100、RTX 4090D 等多种硬件上均具备的高效推理性能,验证了其广泛的部署适用性。PaddleOCR-VL-1.5 具备优秀的工程化和部署友好性,能够灵活适配从数据中心到边缘设备的各种计算环境,为其大规模实际应用奠定了坚实的基础。
表格来源:PaddleOCR-VL-1.5 技术文档
整体来看,PaddleOCR-VL-1.5 在标准文档解析任务上实现了新的 SOTA 精度,其核心突破在于对真实世界复杂物理畸变的卓越鲁棒性。通过架构创新、训练策略优化以及新增印章识别和文本定位能力,该模型成为一个轻量 (0.9B)、高效、多功能的文档解析解决方案,能够为下游 RAG 系统和 LLM 应用提供高保真的知识输入,推动文档智能技术在复杂现实场景中的可靠部署。
OCR 技术发展经历了从最早的模板匹配到现在的端到端深度学习等多个重要发展阶段。近半年来,全球主流模型厂商密集布局 OCR 领域。Mistral AI、字节跳动、腾讯等企业也相继推出新一代 OCR 模型。1 月 27 日,深度求索发布新一代 OCR 模型 DeepSeek-OCR-2,行业竞争持续加剧。
而纵观中国 OCR 发展史,百度一直是这一领域的领航者和重要贡献者。此前,百度推出的开源工具库 PaddleOCR,集成了最先进的检测和识别模型,推动了 OCR 的工业化应用。
随着大模型加速进入金融、政务、制造等高复杂度业务流程,文档解析能力正从 「能用」 走向 「稳定可规模化落地」。
PaddleOCR-VL-1.5 在精度、复杂场景适应性与工程化能力上的系统突破,有望进一步降低产业应用门槛,推动 OCR 技术在真实生产环境中的深度落地。
【文章来源:techweb】
【TechWeb】1 月 30 日消息,百度在 OCR 领域再发力。
29 日,百度正式发布并开源新一代文档解析模型 PaddleOCR-VL-1.5。
该模型以仅 0.9B 参数的轻量架构,在全球权威文档解析评测榜单 OmniDocBench V1.5 中取得全球综合性能第一成绩,整体精度达到 94.5%,不仅超过 Gemini-3-Pro、Qwen3-VL-235B-A22B、GPT-5.2 等模型,也超过了 1 月 27 日 DeepSeek 刚刚发布和开源的 DeepSeek-OCR2 模型。
目前,PaddleOCR-VL-1.5 已全面开源,开发者可通过 GitHub、Hugging Face 获取,并在 PaddleOCR 官网进行在线体验或通过百度智能云千帆平台调用 API 接口。
在线使用/API:https://www.paddleocr.com
开源项目地址:https://github.com/PaddlePaddle/PaddleOCR
模型下载地址:https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
PaddleOCR-VL-1.5 全球首次实现 「异形框定位」
PaddleOCR-VL-1.5 是 2025 年 10 月 16 日百度首次发布并开源的 PaddleOCR-VL 模型的升级版。
相比于上代,PaddleOCR-VL-1.5-0.9B 继承了轻量级架构,NaViT 视觉编码器 + ERNIE-4.5-0.3B 语言模型。
在功能层面,PaddleOCR-VL-1.5 新增多项能力,包括:
进一步集成印章识别、文本检测与识别等任务能力;
针对特殊场景与多语种识别进行系统优化,在生僻字、古籍文献、多语种表格、下划线与复选框等复杂结构识别方面显著提升;
新增对藏语、孟加拉语等语种的支持;
模型还支持跨页表格自动合并与跨页段落标题识别,有效解决长文档解析中的结构断裂问题。
尤其值得注意的是,PaddleOCR-VL-1.5 全球首次实现 OCR 模型的 「异形框定位」 能力,使机器能够精准识别倾斜、弯折、拍照畸变等非规则文档形态,首次让 「歪文档」 实现稳定、可规模化解析。
该技术解决了传统 OCR 模型在移动拍照、扫描件变形、复杂光照等真实场景中因文档形变导致的识别失败问题,可广泛应用于金融票据处理、档案数字化、政务文档流转等场景。
PaddleOCR-VL-1.5 性能超 DeepSeek-OCR2
技术文档内容显示,PaddleOCR-VL-1.5 基于文心大模型进行开发,在 OmniDocBench V1.5 文档解析基准上实现了 94.5% 的最新最先进 (SOTA) 准确率,在文本、公式、表格、阅读顺序所有子任务上均领先。
表格来源:PaddleOCR-VL-1.5 技术文档
公式识别 (FormulaCDM):94.21%,大幅领先所有对比模型,显示出在复杂数学表达式解析上的巨大优势。
表格识别 (TableTEDS):92.76%,同样是最高水平,表明其对表格结构的理解能力极强。
文本与阅读顺序:文本识别 (TextEdit: 0.035) 和阅读顺序 (Reading OrderEdit: 0.042) 误差极低,仅为同类其他模型约一半,保持了顶级水准。
PaddleOCR-VL-1.5 在复杂文档结构还原与版面逻辑理解方面具备更高稳定性,在合同、财报等高复杂度业务场景中拥有更高可用性。
1 月 27 日 DeepSeek 刚刚发布和开源的 DeepSeek-OCR 2 模型,在 OmniDocBench V1.5 的综合得分是 91.09%。这也意味着 PaddleOCR-VL-1.5 性能超过 DeepSeek-OCR 2。
表格来源:1 月 27 日 DeepSeek-OCR 2 模型开源技术文档
另外,为了严格评估模型对真实世界物理畸变的鲁棒性——包括扫描、倾斜、弯曲、屏幕翻拍和光照不均。百度飞桨团队提出了 Real5-OmniDocBench 评测基准。PaddleOCR-VL-1.5 在该基准上取得 92.05% 的整体精度,同样达到 SOTA,在五个子场景下均排名第一,显著优于包括 Qwen3-VL-235B、Gemini-3 Pro 在内的通用大模型。
表格来源:PaddleOCR-VL-1.5 技术文档
另外,在硬件适配方面,PaddleOCR-VL-1.5 模型在 H800、A100、RTX 4090D 等多种硬件上均具备的高效推理性能,验证了其广泛的部署适用性。PaddleOCR-VL-1.5 具备优秀的工程化和部署友好性,能够灵活适配从数据中心到边缘设备的各种计算环境,为其大规模实际应用奠定了坚实的基础。
表格来源:PaddleOCR-VL-1.5 技术文档
整体来看,PaddleOCR-VL-1.5 在标准文档解析任务上实现了新的 SOTA 精度,其核心突破在于对真实世界复杂物理畸变的卓越鲁棒性。通过架构创新、训练策略优化以及新增印章识别和文本定位能力,该模型成为一个轻量 (0.9B)、高效、多功能的文档解析解决方案,能够为下游 RAG 系统和 LLM 应用提供高保真的知识输入,推动文档智能技术在复杂现实场景中的可靠部署。
OCR 技术发展经历了从最早的模板匹配到现在的端到端深度学习等多个重要发展阶段。近半年来,全球主流模型厂商密集布局 OCR 领域。Mistral AI、字节跳动、腾讯等企业也相继推出新一代 OCR 模型。1 月 27 日,深度求索发布新一代 OCR 模型 DeepSeek-OCR-2,行业竞争持续加剧。
而纵观中国 OCR 发展史,百度一直是这一领域的领航者和重要贡献者。此前,百度推出的开源工具库 PaddleOCR,集成了最先进的检测和识别模型,推动了 OCR 的工业化应用。
随着大模型加速进入金融、政务、制造等高复杂度业务流程,文档解析能力正从 「能用」 走向 「稳定可规模化落地」。
PaddleOCR-VL-1.5 在精度、复杂场景适应性与工程化能力上的系统突破,有望进一步降低产业应用门槛,推动 OCR 技术在真实生产环境中的深度落地。
【文章来源:techweb】
【TechWeb】1 月 30 日消息,百度在 OCR 领域再发力。
29 日,百度正式发布并开源新一代文档解析模型 PaddleOCR-VL-1.5。
该模型以仅 0.9B 参数的轻量架构,在全球权威文档解析评测榜单 OmniDocBench V1.5 中取得全球综合性能第一成绩,整体精度达到 94.5%,不仅超过 Gemini-3-Pro、Qwen3-VL-235B-A22B、GPT-5.2 等模型,也超过了 1 月 27 日 DeepSeek 刚刚发布和开源的 DeepSeek-OCR2 模型。
目前,PaddleOCR-VL-1.5 已全面开源,开发者可通过 GitHub、Hugging Face 获取,并在 PaddleOCR 官网进行在线体验或通过百度智能云千帆平台调用 API 接口。
在线使用/API:https://www.paddleocr.com
开源项目地址:https://github.com/PaddlePaddle/PaddleOCR
模型下载地址:https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
PaddleOCR-VL-1.5 全球首次实现 「异形框定位」
PaddleOCR-VL-1.5 是 2025 年 10 月 16 日百度首次发布并开源的 PaddleOCR-VL 模型的升级版。
相比于上代,PaddleOCR-VL-1.5-0.9B 继承了轻量级架构,NaViT 视觉编码器 + ERNIE-4.5-0.3B 语言模型。
在功能层面,PaddleOCR-VL-1.5 新增多项能力,包括:
进一步集成印章识别、文本检测与识别等任务能力;
针对特殊场景与多语种识别进行系统优化,在生僻字、古籍文献、多语种表格、下划线与复选框等复杂结构识别方面显著提升;
新增对藏语、孟加拉语等语种的支持;
模型还支持跨页表格自动合并与跨页段落标题识别,有效解决长文档解析中的结构断裂问题。
尤其值得注意的是,PaddleOCR-VL-1.5 全球首次实现 OCR 模型的 「异形框定位」 能力,使机器能够精准识别倾斜、弯折、拍照畸变等非规则文档形态,首次让 「歪文档」 实现稳定、可规模化解析。
该技术解决了传统 OCR 模型在移动拍照、扫描件变形、复杂光照等真实场景中因文档形变导致的识别失败问题,可广泛应用于金融票据处理、档案数字化、政务文档流转等场景。
PaddleOCR-VL-1.5 性能超 DeepSeek-OCR2
技术文档内容显示,PaddleOCR-VL-1.5 基于文心大模型进行开发,在 OmniDocBench V1.5 文档解析基准上实现了 94.5% 的最新最先进 (SOTA) 准确率,在文本、公式、表格、阅读顺序所有子任务上均领先。
表格来源:PaddleOCR-VL-1.5 技术文档
公式识别 (FormulaCDM):94.21%,大幅领先所有对比模型,显示出在复杂数学表达式解析上的巨大优势。
表格识别 (TableTEDS):92.76%,同样是最高水平,表明其对表格结构的理解能力极强。
文本与阅读顺序:文本识别 (TextEdit: 0.035) 和阅读顺序 (Reading OrderEdit: 0.042) 误差极低,仅为同类其他模型约一半,保持了顶级水准。
PaddleOCR-VL-1.5 在复杂文档结构还原与版面逻辑理解方面具备更高稳定性,在合同、财报等高复杂度业务场景中拥有更高可用性。
1 月 27 日 DeepSeek 刚刚发布和开源的 DeepSeek-OCR 2 模型,在 OmniDocBench V1.5 的综合得分是 91.09%。这也意味着 PaddleOCR-VL-1.5 性能超过 DeepSeek-OCR 2。
表格来源:1 月 27 日 DeepSeek-OCR 2 模型开源技术文档
另外,为了严格评估模型对真实世界物理畸变的鲁棒性——包括扫描、倾斜、弯曲、屏幕翻拍和光照不均。百度飞桨团队提出了 Real5-OmniDocBench 评测基准。PaddleOCR-VL-1.5 在该基准上取得 92.05% 的整体精度,同样达到 SOTA,在五个子场景下均排名第一,显著优于包括 Qwen3-VL-235B、Gemini-3 Pro 在内的通用大模型。
表格来源:PaddleOCR-VL-1.5 技术文档
另外,在硬件适配方面,PaddleOCR-VL-1.5 模型在 H800、A100、RTX 4090D 等多种硬件上均具备的高效推理性能,验证了其广泛的部署适用性。PaddleOCR-VL-1.5 具备优秀的工程化和部署友好性,能够灵活适配从数据中心到边缘设备的各种计算环境,为其大规模实际应用奠定了坚实的基础。
表格来源:PaddleOCR-VL-1.5 技术文档
整体来看,PaddleOCR-VL-1.5 在标准文档解析任务上实现了新的 SOTA 精度,其核心突破在于对真实世界复杂物理畸变的卓越鲁棒性。通过架构创新、训练策略优化以及新增印章识别和文本定位能力,该模型成为一个轻量 (0.9B)、高效、多功能的文档解析解决方案,能够为下游 RAG 系统和 LLM 应用提供高保真的知识输入,推动文档智能技术在复杂现实场景中的可靠部署。
OCR 技术发展经历了从最早的模板匹配到现在的端到端深度学习等多个重要发展阶段。近半年来,全球主流模型厂商密集布局 OCR 领域。Mistral AI、字节跳动、腾讯等企业也相继推出新一代 OCR 模型。1 月 27 日,深度求索发布新一代 OCR 模型 DeepSeek-OCR-2,行业竞争持续加剧。
而纵观中国 OCR 发展史,百度一直是这一领域的领航者和重要贡献者。此前,百度推出的开源工具库 PaddleOCR,集成了最先进的检测和识别模型,推动了 OCR 的工业化应用。
随着大模型加速进入金融、政务、制造等高复杂度业务流程,文档解析能力正从 「能用」 走向 「稳定可规模化落地」。
PaddleOCR-VL-1.5 在精度、复杂场景适应性与工程化能力上的系统突破,有望进一步降低产业应用门槛,推动 OCR 技术在真实生产环境中的深度落地。
【文章来源:techweb】
【TechWeb】1 月 30 日消息,百度在 OCR 领域再发力。
29 日,百度正式发布并开源新一代文档解析模型 PaddleOCR-VL-1.5。
该模型以仅 0.9B 参数的轻量架构,在全球权威文档解析评测榜单 OmniDocBench V1.5 中取得全球综合性能第一成绩,整体精度达到 94.5%,不仅超过 Gemini-3-Pro、Qwen3-VL-235B-A22B、GPT-5.2 等模型,也超过了 1 月 27 日 DeepSeek 刚刚发布和开源的 DeepSeek-OCR2 模型。
目前,PaddleOCR-VL-1.5 已全面开源,开发者可通过 GitHub、Hugging Face 获取,并在 PaddleOCR 官网进行在线体验或通过百度智能云千帆平台调用 API 接口。
在线使用/API:https://www.paddleocr.com
开源项目地址:https://github.com/PaddlePaddle/PaddleOCR
模型下载地址:https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
PaddleOCR-VL-1.5 全球首次实现 「异形框定位」
PaddleOCR-VL-1.5 是 2025 年 10 月 16 日百度首次发布并开源的 PaddleOCR-VL 模型的升级版。
相比于上代,PaddleOCR-VL-1.5-0.9B 继承了轻量级架构,NaViT 视觉编码器 + ERNIE-4.5-0.3B 语言模型。
在功能层面,PaddleOCR-VL-1.5 新增多项能力,包括:
进一步集成印章识别、文本检测与识别等任务能力;
针对特殊场景与多语种识别进行系统优化,在生僻字、古籍文献、多语种表格、下划线与复选框等复杂结构识别方面显著提升;
新增对藏语、孟加拉语等语种的支持;
模型还支持跨页表格自动合并与跨页段落标题识别,有效解决长文档解析中的结构断裂问题。
尤其值得注意的是,PaddleOCR-VL-1.5 全球首次实现 OCR 模型的 「异形框定位」 能力,使机器能够精准识别倾斜、弯折、拍照畸变等非规则文档形态,首次让 「歪文档」 实现稳定、可规模化解析。
该技术解决了传统 OCR 模型在移动拍照、扫描件变形、复杂光照等真实场景中因文档形变导致的识别失败问题,可广泛应用于金融票据处理、档案数字化、政务文档流转等场景。
PaddleOCR-VL-1.5 性能超 DeepSeek-OCR2
技术文档内容显示,PaddleOCR-VL-1.5 基于文心大模型进行开发,在 OmniDocBench V1.5 文档解析基准上实现了 94.5% 的最新最先进 (SOTA) 准确率,在文本、公式、表格、阅读顺序所有子任务上均领先。
表格来源:PaddleOCR-VL-1.5 技术文档
公式识别 (FormulaCDM):94.21%,大幅领先所有对比模型,显示出在复杂数学表达式解析上的巨大优势。
表格识别 (TableTEDS):92.76%,同样是最高水平,表明其对表格结构的理解能力极强。
文本与阅读顺序:文本识别 (TextEdit: 0.035) 和阅读顺序 (Reading OrderEdit: 0.042) 误差极低,仅为同类其他模型约一半,保持了顶级水准。
PaddleOCR-VL-1.5 在复杂文档结构还原与版面逻辑理解方面具备更高稳定性,在合同、财报等高复杂度业务场景中拥有更高可用性。
1 月 27 日 DeepSeek 刚刚发布和开源的 DeepSeek-OCR 2 模型,在 OmniDocBench V1.5 的综合得分是 91.09%。这也意味着 PaddleOCR-VL-1.5 性能超过 DeepSeek-OCR 2。
表格来源:1 月 27 日 DeepSeek-OCR 2 模型开源技术文档
另外,为了严格评估模型对真实世界物理畸变的鲁棒性——包括扫描、倾斜、弯曲、屏幕翻拍和光照不均。百度飞桨团队提出了 Real5-OmniDocBench 评测基准。PaddleOCR-VL-1.5 在该基准上取得 92.05% 的整体精度,同样达到 SOTA,在五个子场景下均排名第一,显著优于包括 Qwen3-VL-235B、Gemini-3 Pro 在内的通用大模型。
表格来源:PaddleOCR-VL-1.5 技术文档
另外,在硬件适配方面,PaddleOCR-VL-1.5 模型在 H800、A100、RTX 4090D 等多种硬件上均具备的高效推理性能,验证了其广泛的部署适用性。PaddleOCR-VL-1.5 具备优秀的工程化和部署友好性,能够灵活适配从数据中心到边缘设备的各种计算环境,为其大规模实际应用奠定了坚实的基础。
表格来源:PaddleOCR-VL-1.5 技术文档
整体来看,PaddleOCR-VL-1.5 在标准文档解析任务上实现了新的 SOTA 精度,其核心突破在于对真实世界复杂物理畸变的卓越鲁棒性。通过架构创新、训练策略优化以及新增印章识别和文本定位能力,该模型成为一个轻量 (0.9B)、高效、多功能的文档解析解决方案,能够为下游 RAG 系统和 LLM 应用提供高保真的知识输入,推动文档智能技术在复杂现实场景中的可靠部署。
OCR 技术发展经历了从最早的模板匹配到现在的端到端深度学习等多个重要发展阶段。近半年来,全球主流模型厂商密集布局 OCR 领域。Mistral AI、字节跳动、腾讯等企业也相继推出新一代 OCR 模型。1 月 27 日,深度求索发布新一代 OCR 模型 DeepSeek-OCR-2,行业竞争持续加剧。
而纵观中国 OCR 发展史,百度一直是这一领域的领航者和重要贡献者。此前,百度推出的开源工具库 PaddleOCR,集成了最先进的检测和识别模型,推动了 OCR 的工业化应用。
随着大模型加速进入金融、政务、制造等高复杂度业务流程,文档解析能力正从 「能用」 走向 「稳定可规模化落地」。
PaddleOCR-VL-1.5 在精度、复杂场景适应性与工程化能力上的系统突破,有望进一步降低产业应用门槛,推动 OCR 技术在真实生产环境中的深度落地。