

全球人工智能算力芯片龙头英伟达周二宣布,推出专为长上下文工作负载设计的专用 GPU Rubin CPX,用于翻倍提升当前 AI 推理运算的工作效率,特别是编程、视频生成等需要超长上下文窗口的应用。
英伟达 CEO 黄仁勋表示,CPX 是首款专为需要一次性处理大量知识 (数百万级别 tokens),并进行人工智能推理的模型而构建的芯片。
需要说明的是,Rubin 就是英伟达将在明年发售的下一代顶级算力芯片,所以基于 Rubin 的 CPX 预计也要到 2026 年底出货。下一代英伟达旗舰 AI 服务器的全称叫做 NVIDIA Vera Rubin NVL144 CPX——集成 36 个 Vera CPU、144 块 Rubin GPU 和 144 块 Rubin CPX GPU。

(NVIDIA Vera Rubin NVL144 CPX 机架与托盘,来源:公司博客)
英伟达透露,搭载 Rubin CPX 的 Rubin 机架在处理大上下文窗口时的性能,能比当前旗舰机架 GB300 NVL72 高出最多 6.5 倍。
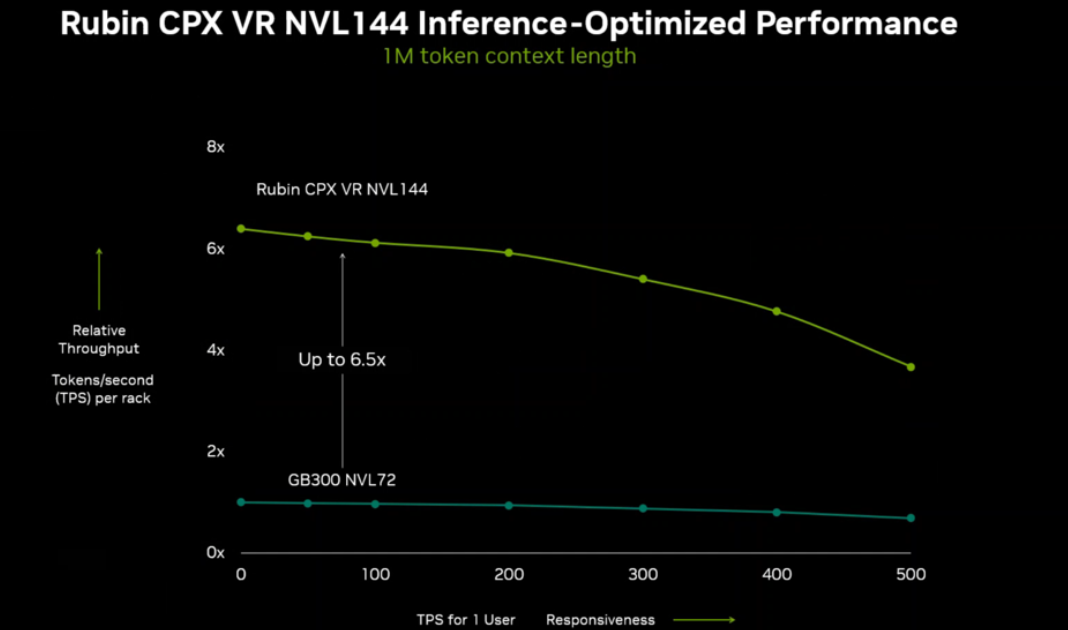
据悉,下一代旗舰机架将提供 8exaFLOPs 的 NVFP4 算力,比 GB300 NVL72 高出 7.5 倍。同时单个机架就能提供 100TB 的高速内存和 1.7PB/s 的内存带宽。
言归正传,英伟达之所以要在 Rubin GPU 边上再配一块 Rubin CPX GPU,自然是为了显著提升数据中心的算力效率——用户购买英伟达的芯片将能赚到更多的钱。英伟达表示,部署价值 1 亿美元的新芯片,将能为客户带来 50 亿美元的收入。
为何需要不同的 GPU?
作为行业首创之举,英伟达的新品在硬件层面上分拆了人工智能推理的计算负载。
英伟达介绍称,推理过程包括两个截然不同的阶段:上下文阶段与生成阶段,两者对基础设施的要求本质上完全不同。
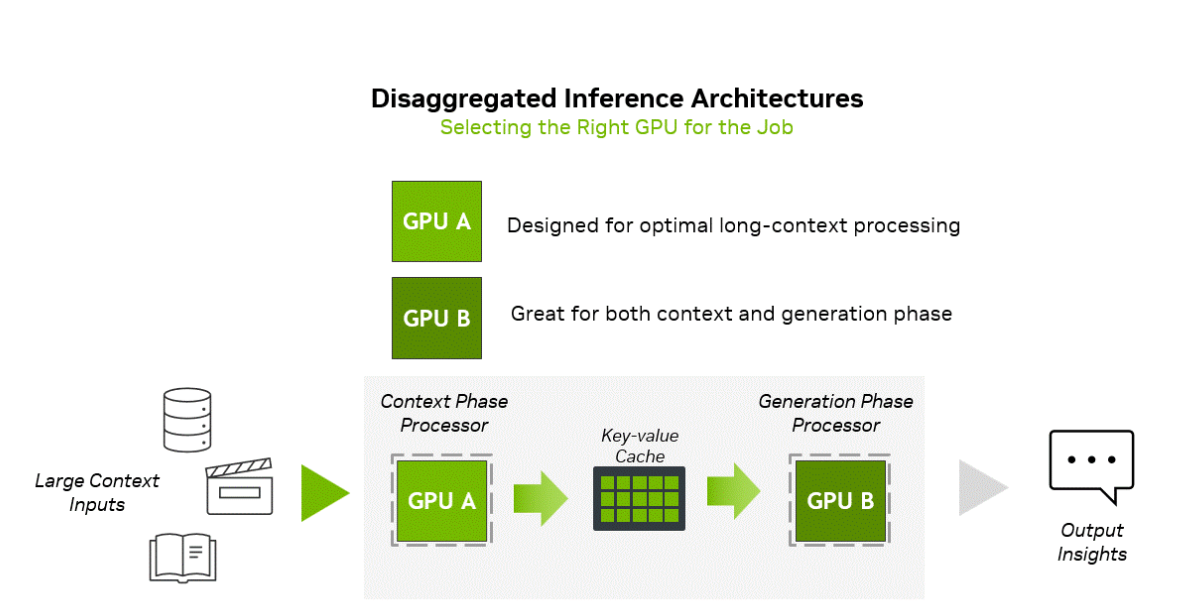
上下文阶段属于计算受限 (compute-bound),需要高吞吐量的处理能力来摄取并分析大量输入数据,从而生成首个输出 token。相反,生成阶段则属于内存带宽受限 (memory bandwidth-bound),依赖高速的内存传输和高带宽互联 (如 NVLink),以维持逐个 token 的输出性能。
当前顶级的 GPU 都是为了内存和网络限制的生成阶段设计,配备昂贵的 HBM 内存,然而在解码阶段并不需要这些内存。因此,通过分离式处理这两个阶段,并针对性地优化计算与内存资源,将显著提升算力的利用率。
据悉,Rubin CPX 专门针对 「数百万 tokens」 级别的长上下文性能进行优化,具备 30petaFLOPs 的 NVFP4 算力、128GB GDDR7 内存。
英伟达估计,大约有 20% 的 AI 应用会 「坐等」 首个 token 出现。例如解码 10 万行代码可能需要 5-10 分钟。而多帧、多秒的视频,预处理和逐帧嵌入会迅速增加延迟,这也是为什么当前的视频大模型通常仅用于制作短片。
英伟达计划以两种形式提供 Rubin CPX,一种是与 Vera Rubin 装在同一个托盘上。对于已经下单 NVL144 的用户,英伟达也会单独出售一整个机架的 CPX 芯片,数量正好匹配 Rubin 机架。

(财联社)
文章转载自 东方财富
