
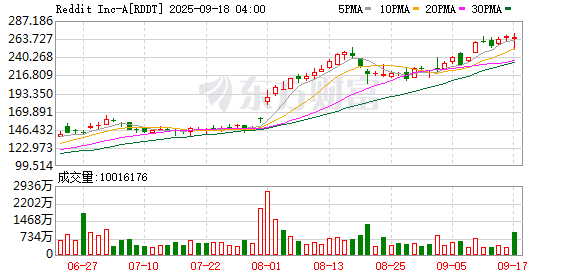
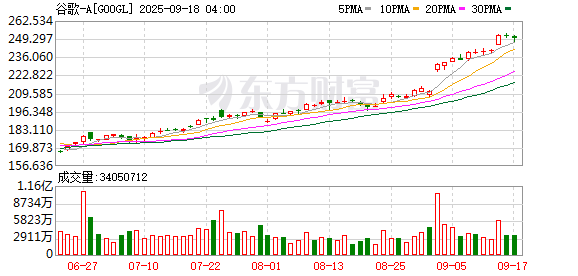
Reddit 正在与 Alphabet 旗下谷歌展开初步谈判,寻求达成新一轮内容授权协议。随着其数据在搜索结果和生成式 AI 训练中扮演越来越重要的角色,Reddit 希望在未来的交易中获得更高收益。
据知情人士透露,在一年半前与谷歌达成首份内容授权协议 (据称价值约 6000 万美元) 后,Reddit 正与谷歌讨论将数据更深入地整合进其 AI 产品。
Reddit 提出了一种新的合作模式,旨在鼓励用户更多地参与平台热门论坛的发帖与互动,从而借助谷歌的流量带动平台增长,并为未来 AI 训练提供更多数据和内容。
此外,Reddit 还计划与谷歌和已达成类似协议的 OpenAI 探讨未来的交易结构,或将引入动态定价机制。随着 Reddit 内容在 AI 问答中的重要性提升,这家公司希望能够获得更高的授权收益。
这意味着 Reddit 正尝试摆脱以往单纯的一次性授权模式。传统上,AI 公司会支付固定费用,以便在其产品中展示 Reddit 内容,或用于训练 AI 模型。但 Reddit 方面认为,这类条款并不能真实体现其数据对这些平台的价值。
Reddit 此前与谷歌和 OpenAI 达成的首批数据协议仍在有效期内。根据其去年 IPO 前披露的文件,2024 年 1 月,Reddit 与谷歌、OpenAI 等签订的多份内容授权合同,总价值高达 2.03 亿美元,期限为两至三年。
大语言模型是 OpenAI 的 ChatGPT、谷歌搜索 「AI 概览」 及其 Gemini 助手的底层技术,训练依赖于从互联网获取的大规模数据。Reddit 凭借独特的用户生成内容形式,涵盖大量小众话题和真实用户体验,不仅是训练 AI 模型的重要信息源,也是 AI 聊天机器人在实时回答用户问题时的常见引用来源,有时甚至会直接链接到 Reddit 讨论帖。
随着 AI 公司寻求合法的数据来源,此类授权协议正越来越普遍。OpenAI 已与包括德国阿克塞尔·施普林格集团、《时代》 杂志及 Conde Nast 在内的多家媒体出版商达成合作,以使用其内容训练 ChatGPT。
与此同时,一些媒体集团则指控 AI 公司非法使用其数据。纽约时报与潘斯基传媒集团已分别起诉 OpenAI 和谷歌,称其未经许可擅自获取内容,且抢走了网站流量。
Reddit 自己也对 OpenAI 的竞争对手 Anthropic 提起诉讼,指控其非法抓取平台数据训练模型。而 Anthropic 近期同意向一批作者支付至少 15 亿美元,达成美国史上最大规模之一的版权和解,进一步抬高了 AI 公司的数据获取成本。
根据分析公司 Profound AI 的数据,Reddit 仍是各大 AI 公司中被引用最频繁的来源之一。然而,该公司高管们注意到,来自谷歌的流量价值有限,因为许多通过搜索结果进入的用户只为寻找具体答案,很少转化为活跃的 Reddit 用户。
目前,Reddit 正与谷歌的产品团队接洽,寻求引导更多用户深入其社区生态系统的方式。据知情人士称,作为交换,Reddit 也希望能向 AI 合作伙伴提供更多高质量数据。双方讨论进展积极。
Reddit 首席运营官 Jen Wong 此前表示:「我们仍处在数据授权交易的过程中,也在不断学习。但目前来看,Reddit 的数据被高度引用且极具价值,我们将会持续进行评估。」
(财联社)
文章转载自 东方财富