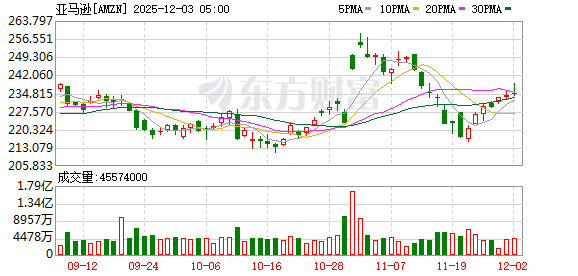
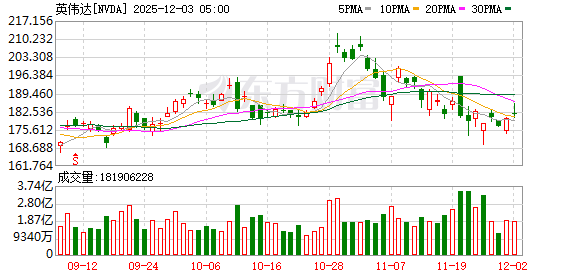
北京时间周三凌晨,全球云计算「一哥」 亚马逊AWS 在 re:Invent 大会期间宣布,华尔街翘首期待的新一代自研 AI 芯片Trainium3 正式公开上市。
综合公司介绍,Trainium3 是亚马逊首款 3nm 制程芯片。与上一代 Trainium 芯片相比,Trainium3 计算性能最高提升 4.4 倍,能效提升 4 倍,内存带宽几乎提升 4 倍,主打 AI 算力竞争的性价比赛道。由 Trainium3 组成的 UltraServer 系统还可以互联,每台可容纳 144 枚芯片,为单个应用提供多达 100 万枚 Trainium3 芯片,为上一代的 10 倍。
公司表示,与同样使用图形处理单元 (GPU) 的系统相比,训练和运行 AI 模型的成本能够降低最多 50%。
当然,指望亚马逊 Trainium3 与谷歌 TPU 一战,甚至 「挑战英伟达」 的投资者可能会有些失望,毕竟没有任何资料显示这款芯片除了 「性价比」 之外的其他优势。
亚马逊拒绝透露新款 AI 芯片与谷歌、英伟达最新产品的基准性能对比,也未披露功耗参数。目前我们仅知道每枚芯片集成 144GB 的高带宽内存,而谷歌最新的 Ironwood TPU 为 192GB,英伟达的 Blackwell GB300 则最高可达 288GB。
负责 Trainium 项目的 AWS 副总裁兼首席架构师 Ron Diamant 也直言:「我不认为我们会试图取代英伟达」。
Diamant 进一步表示,归根结底,这款自研芯片最大的优势就是性价比。他的主要目标是为客户在不同的计算工作负载上提供更多选择。
对于亚马逊的 AI 芯片而言,最大的短板并不是芯片本身,而是亚马逊缺乏足够有深度且易于使用的软件库。
除了亚马逊自己以及公司大力投资的 AI 初创企业 Anthropic 外,现在几乎找不到使用 Trainium 芯片的知名公司。
而 Anthropic 也在 10 月表示,将采购最多 100 万块谷歌的 TPU,又在 11 月宣布与英伟达签署投资入股协议,并将进一步购买英伟达芯片的算力。不过 Anthropic 也强调,亚马逊仍然是其 「主要的训练合作伙伴和云服务提供商」, 预计到年底将使用超过一百万颗 Trainium 2 芯片。
使用人工智能赋能施工设备自动化的 Bedrock Robotics 介绍称,公司基础设施运行在 AWS 服务器上,但在为挖掘机构建引导模型时,就得用英伟达芯片。公司首席技术官 Kevin Peterson 总结称:「我们需要它既高性能又易于使用,那就是英伟达。」
亚马逊似乎也意识到了这个问题。在 Trainium3 的公告中,公司特别强调 Trainium4 已在研发中,最大的亮点是 「能与英伟达芯片协同工作」。
公司表示,Trainium4 将支持英伟达 NVLink Fusion 高速芯片互连技术,最终形成一种兼顾 GPU 与 Trainium 服务器的经济高效机架级 AI 基础设施。
英伟达介绍称,NVLink Fusion 的核心是 NVLink Fusion chiplet,超大规模云服务商可以将该 chiplet 嵌入其定制 ASIC 设计中,以连接 NVLink 规模化互联和 NVLink 交换机。
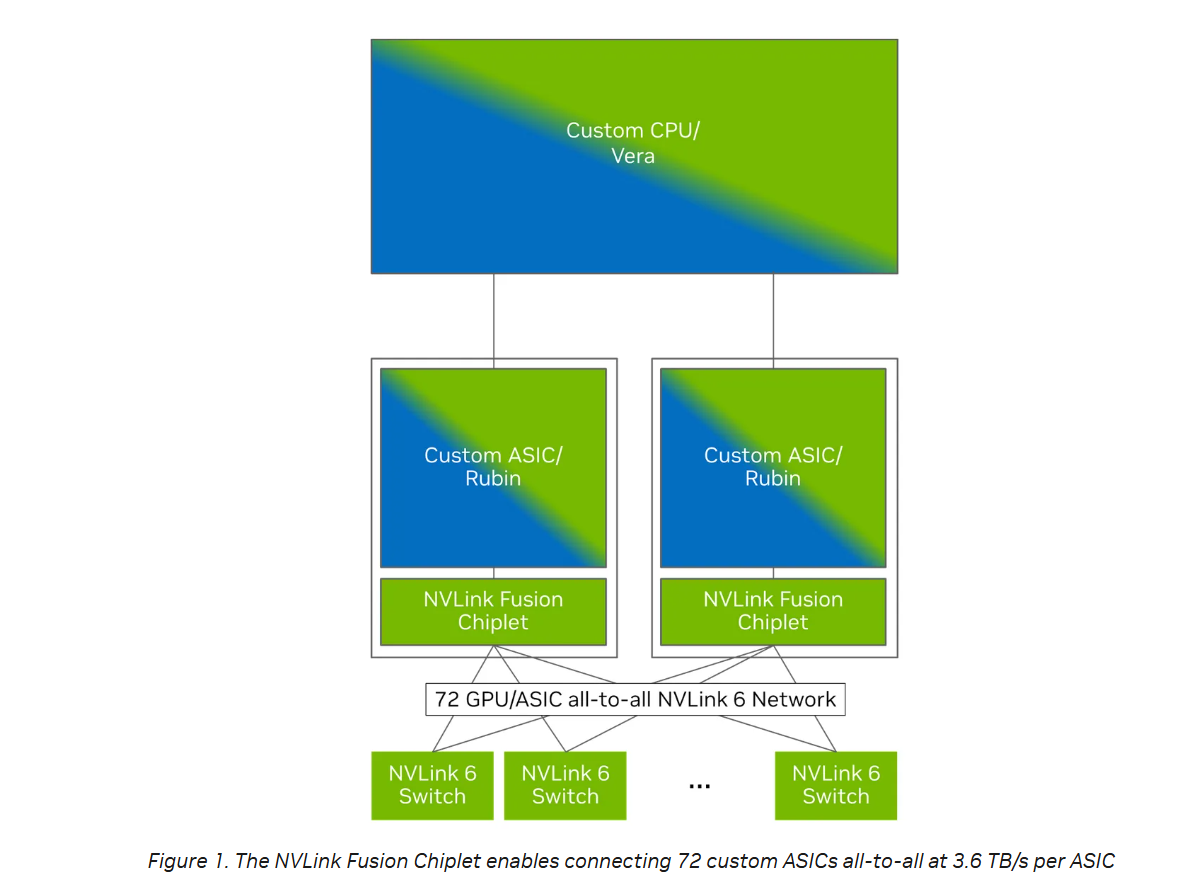
(NVLink Fusion 芯片组使 72 个定制 ASIC 以每个 ASIC 3.6 TB/s 的带宽实现全互联,来源:英伟达)
这意味着,基于 Trainium4 的系统将能够与英伟达 GPU 互操作,并提升整体性能,同时依然使用亚马逊自研的、更低成本的服务器机柜技术。这也将使得那些以英伟达 GPU 为核心构建的大型 AI 应用,更容易迁移到 AWS。

(财联社)
文章转载自 东方财富