

据央视新闻,当地时间 11 月 11 日,德国慕尼黑地方法院裁定,美国开放人工智能研究中心 (OpenAI) 未经授权使用德国音乐人创作的歌词,构成侵犯版权,应向德国一家主要音乐版权协会所代表的原告支付赔偿金。这起诉讼可能成为欧洲对生成式人工智能技术版权监管的重要判例。
案件始于德国音乐演出和作品复制权协会 2024 年 11 月提起的诉讼。该协会是欧洲最大音乐著作权集体管理组织之一,成员包括德国著名音乐人赫伯特·格罗内迈尔在内约十万名词曲作者和出版人。
据报道,该协会指控 OpenAI 在未经许可、未付费情况下 「系统性」 使用了协会版权曲库内容用于训练人工智能模型 ChatGPT,涉及格罗内迈尔畅销作品等 9 首德国歌曲的歌词。对此,OpenAI 回应说,原告指控 「误解了 ChatGPT 的工作原理」,其大语言模型 「并不存储或复制具体数据,只反映学习过的内容」,生成内容的责任应由用户承担。
法院认定,OpenAI 语言模型中的记忆行为,以及 ChatGPT 输出中对歌词的再现,均构成侵犯版权。该裁决可上诉。
OpenAI 发言人说,公司不同意该裁决结果,正在考虑对策。公司同时表示,上述裁决 「仅涉及少量歌词」,不影响德国数以百万计个人和企业用户使用该公司技术。
报道称,这起诉讼的最终结果可能在欧洲打造一个关于人工智能技术企业如何使用版权内容的参考范例。今年早些时候,印度宝莱坞主要唱片公司向新德里一家法院申请加入一宗针对 OpenAI 的版权诉讼,指控其在训练人工智能模型时未经授权使用录音内容。
另据央视新闻此前消息,「只需一句话和几秒钟,你就能生成宫崎骏动画」,这并不是玩笑。由于美国开放人工智能研究中心 (Open AI) 的图像生成技术可轻松生成大批具有宫崎骏画风的动画图片,引发了包括宫崎骏所在的吉卜力工作室等日本多家 IP 出版公司愤怒。他们通过日本内容产品海外流通促进机构,向 Open AI 公司致函,要求该公司停止在未经授权的情况下,使用相关内容产品训练 AI 模型。

图片来源:央视新闻
日本内容产品海外流通促进机构 (简称 CODA) 在致函中称,经核实,Open AI 公司于 9 月底推出的人工智能影片生成工具 Sora 2 已生成大量与日本现有内容产品相同或高度相似的影像。该机构认为,这是源于 Sora 2 将日本内容产品作为 AI 学习及训练数据的结果,而其学习过程中的复制行为,本身已涉嫌构成著作权侵害。

图片来源:央视新闻
针对 Open AI 此前通过媒体披露的应对方案,也就是 「著作权人可通过申请 『选择退出』 机制来解决相关问题」,CODA 表示明确反对。据了解,「选择退出」 机制的特点在于,要求著作权人明确有效地表示 「未经授权不得使用」,否则将被视为 「默认同意」。对此,CODA 强调,这一解释与日本著作权制度存在根本冲突,日本法律明确规定,使用著作物原则上必须获得事前许可,并不存在通过事后异议申诉即可免除侵权责任的机制。
值得关注的是,日本内容行业对 AI 侵权的反对已形成合力。除 CODA 外,包含小学馆在内的 17 家日本出版机构,以及日本动画协会、日本漫画家协会,已于 10 月 31 日联合发表声明,明确表态绝不容忍任何侵犯著作权的行为。
AI 生成歌手签百万合约、影视从业者罢工抗议、主流媒体集体起诉 ——当人工智能冲击创意产业,版权归属、权益保障的争议持续发酵,成为行业无法回避的核心焦点。
克珊妮娅·莫内特是位由 AI 生成的 R&B 歌手。她签下了价值数百万美元的唱片合约,作品在社交媒体和流媒体平台迅速走红。日前,莫内特登上知名音乐榜单 「公告牌」,成为首位登上该榜的 AI 歌手,不过她的走红也引发了巨大争议。
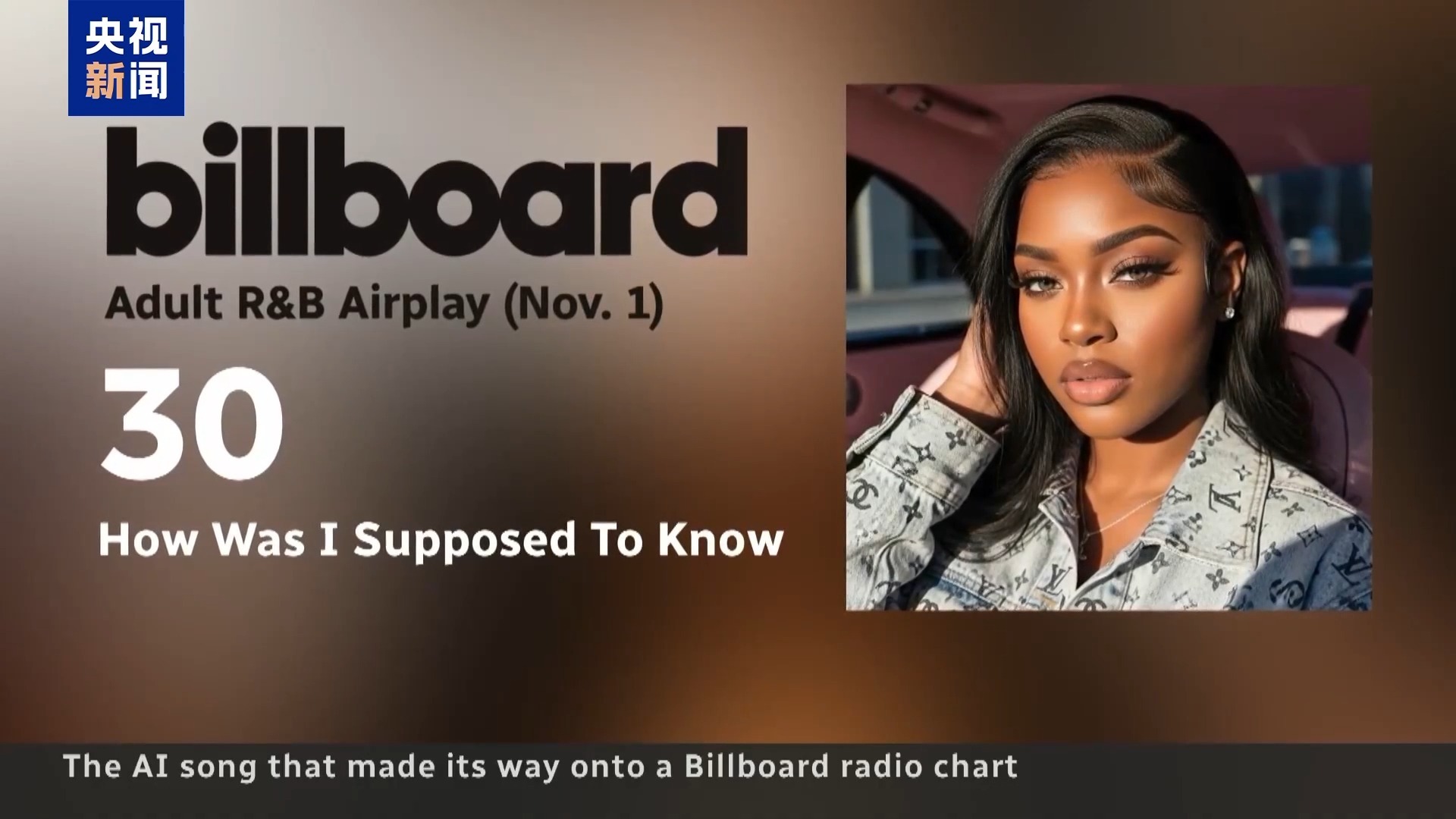
图片来源:央视新闻
2023 年 7 月,美国演员工会宣布支持美国编剧协会,正式加入罢工行列,这也是 60 多年来好莱坞最大的两个工会组织首次同时罢工。此次联合罢工的核心诉求之一是建立有效机制,减少人工智能对影视从业者的冲击。
如何在人工智能技术和文化创意产业之间建立一份符合双方规范的 「契约」 呢?
数字经济学者刘兴亮指出,人工智能在显著降低创作门槛、提升效率的同时,也潜藏着一系列结构性风险。分析认为,其核心困境主要体现在两方面:
其一,独创性的消解——当机器能够轻易模仿并量产任何艺术风格时,传统创作者赖以生存的 「唯一性」 将被极大削弱,独特的地域风格和传统文化元素面临被无限复制的风险;
其二,权力的转移——创意产业的竞争格局,可能从 「内容创作」 的竞争,异化为 「谁掌握模型、平台与分发渠道」 的竞争,这将使拥有强大 AI 能力的大型科技公司占据绝对主导地位。
刘兴亮表示,要解决这一问题,就要提前搭建规则框架,在人工智能技术和文化创意产业之间建立一份符合双方规范的 「公平契约」。
为在人工智能与创意产业间建立公平的 「契约」,刘兴亮提出以下建议:
第一,建立事前授权机制。创作者或版权方应明确授权范围,要求使用方支付费用、约定分成比例并说明具体用途,方可将其作品或风格用于 AI 训练。
第二,完善事后补偿模式。如 AI 使用版权内容进行训练,应支付训练数据费;若利用特定风格生成商业作品,则需与原作者按约定比例分账。
第三,推动人机协作式创作。创作者可主导构思、提示与风格设定,由 AI 生成初稿,再由创作者深化内容、注入故事性,以此体现人的创作价值。
第四,强化合同约束与标识规范。合同中须明确限定可使用及禁用的作品与风格;AI 生成内容必须明确标注为人工智能创作,且不得生成与原作高度相似的角色或画面。
第五,加强政策支持。行业主管部门与协会可以推动建立集体授权平台,构建训练数据版权许可制度,提高创作者群体的话语权。

(每日经济新闻)
文章转载自 东方财富
